

Marking rows as the first, last, newest, or oldest in a group helps with reporting, ranking, and data tracking. Instead of pulling every record and checking them later in application code, SQL can add boolean or status flags directly in the result set. That cuts down on extra work and gives queries results that already carry context about where each row falls inside a group. The mechanics that make this possible come from ordering, partitioning, and ranking functions that are part of modern SQL standards.
How Row Position Is Calculated
Relational databases treat rows as a collection without any guaranteed order until you give them one. That’s why functions for ranking and partitioning are only meaningful once an order has been set. When you ask for the first or last row in a group, the database has to put the records into a sequence before it can decide which belongs at the top or bottom. After that sequence is created, other functions can assign numbers, compare values, or add flags that mark positions. This chain of steps explains how SQL turns unordered sets into ordered results that carry context.
Sorting Mechanics
Sorting is the foundation for everything else. Without it, the database engine doesn’t know which row comes first or last. When you write a query with ORDER BY, the engine either walks through an index that matches the order or runs a sorting operation in memory or temporary space. The efficiency depends on whether an index is present and how large the dataset is.
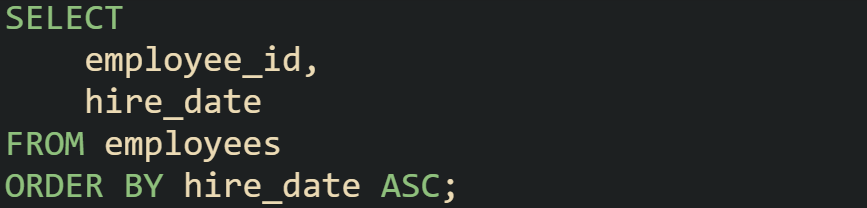
This query arranges employees by their hire date. The first row returned will be the earliest hire, and the last will be the most recent. With an index on hire_date, the database can avoid sorting manually and simply scan the index in order. Without that index, it has to arrange all rows itself, which can take longer.
When combined with multiple columns, order can be layered. An example would be sorting employees by department first, and then by hire date within that department:
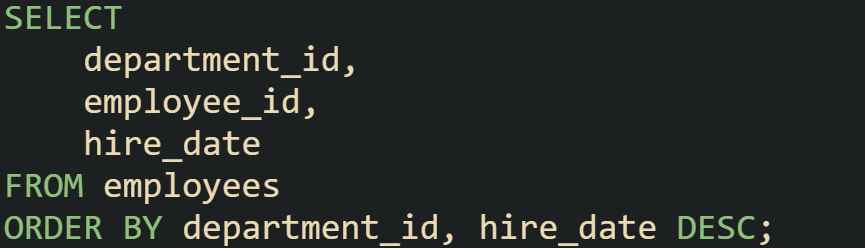
This makes the newest hire in each department appear first within that group. Ordering like this lays the groundwork for the functions that flag first and last rows later in the query.
Group Partitioning
Grouping creates logical slices of data that can be worked with separately. When a partition is applied, rows are divided into buckets that share the same values in one or more columns. Every bucket can then be ordered and ranked independently of the others.
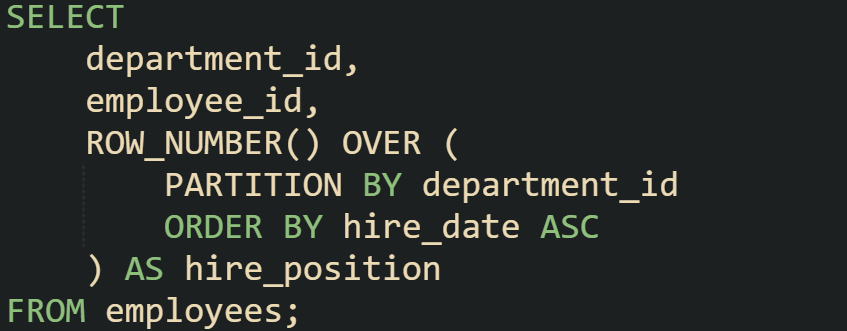
Here, each department is treated as its own partition. Inside those partitions, employees are numbered from earliest hire to latest. Without the partition, the numbering would run across the entire table. That difference matters when you only care about relative positions inside a group. Partitioning doesn’t always have to be tied to departments or categories. It could be used for projects, customers, or even time intervals like month or year. Once the partitions are set, every group is handled as if it were its own smaller table, giving meaning to comparisons like first and last within the group.
Ranking Functions
Ranking functions build on sorting and partitioning by assigning numeric values to each row. SQL supports several ranking methods, but the one most suited for identifying first and last rows is ROW_NUMBER(). It provides a strictly increasing number without duplicates inside a partition, which makes it easy to test for the value 1 to find the first row.
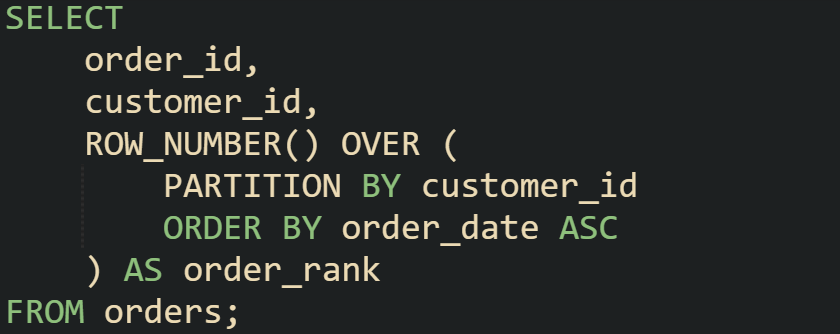
This assigns a sequential number to every order for a customer. If you filter where order_rank = 1, you’ll get the earliest order per customer.
Another ranking function is RANK(), which accounts for ties. If two rows share the same value in the ordering column, they both get the same rank, and the next rank number is skipped. DENSE_RANK() works similarly but doesn’t skip numbers. These two are better suited for situations where ties are meaningful, like scoring or competition standings. For first and last row flags, ROW_NUMBER() usually provides the most precise results.

For this code, competitors with the same score share the same rank. That behavior differs from ROW_NUMBER(), which would assign unique numbers regardless of ties.
Boolean Flags With CASE Expressions
Boolean or status flags turn numeric rankings into simple values that are easier to work with downstream. They add meaning directly to each row by marking which is first, last, oldest, or newest. CASE expressions are the most direct way to do this.
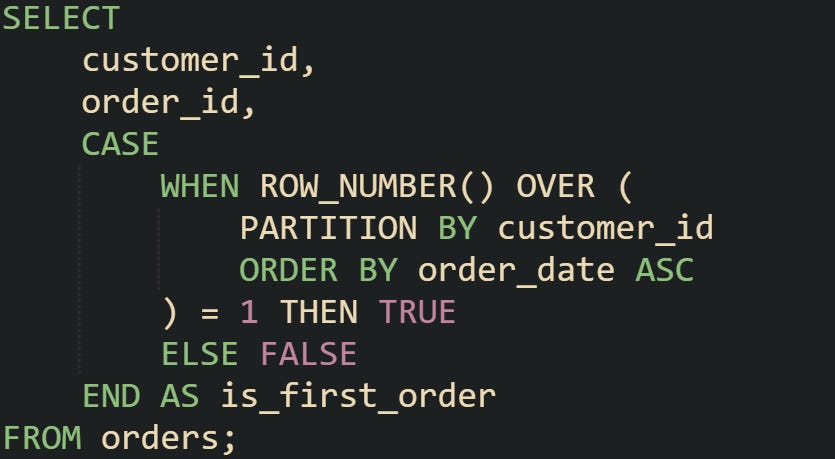
That query adds a flag to each row, and the earliest order per customer gets marked as TRUE. When applied across many customers, this makes it simple to filter or aggregate later without rerunning ranking logic.
You can also flip the order direction to tag the newest row in each group:
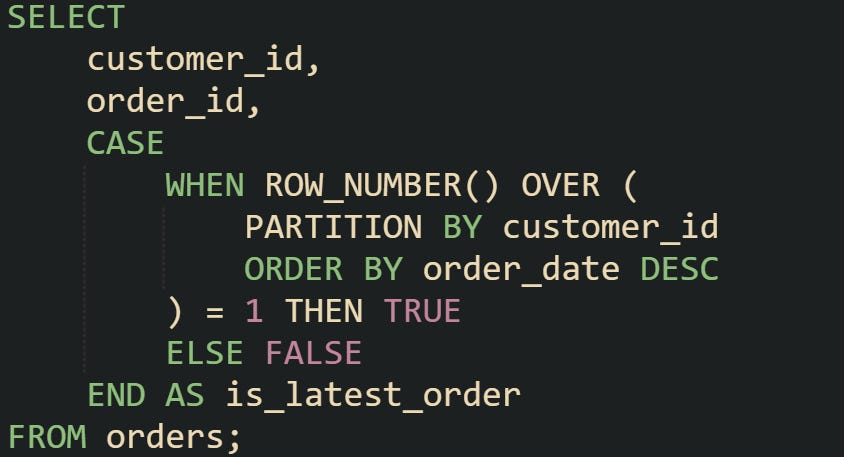
In both cases the database is doing the heavy lifting of ranking and then applying a conditional check that transforms numeric ranks into boolean flags. That transformation makes the query output more practical, because the flag can be consumed directly by reports or joined with other queries without needing another layer of ranking.
Techniques for Marking First and Last Rows
With the mechanics of ordering and ranking in place, different strategies can be applied to tag rows as first or last. Some techniques focus on producing explicit boolean flags, while others filter data down to only the rows of interest. Which method fits best depends on the database system, the size of the dataset, and how the result set is going to be used later.
Using ROW_NUMBER To Create First Flags Or Last Flags
ROW_NUMBER() is one of the most reliable ways to establish position in a group. Because it generates a sequence without ties, it makes it easy to test whether a row is at the start or end of its partition. With this approach, you don’t need to store extra metadata on the table itself, because everything is handled within the query.
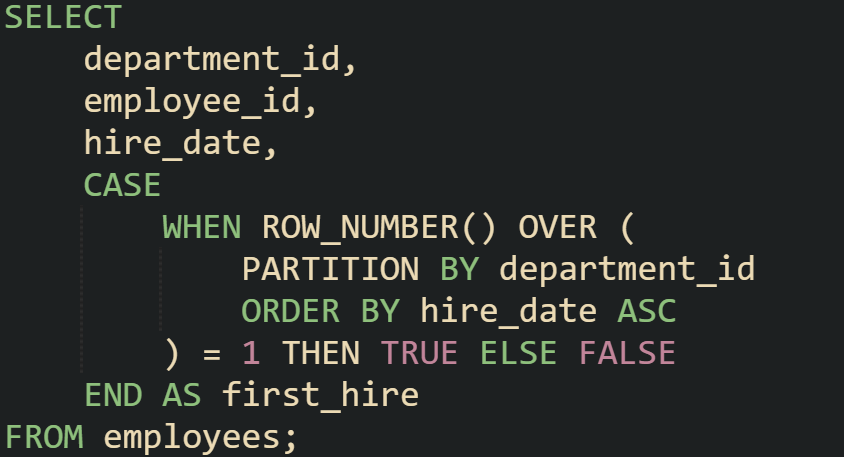
That query marks the first hire in every department. Flipping the order to descending marks the most recent hire. If you want both ends of the sequence in one step, you can add two separate expressions with different order directions.
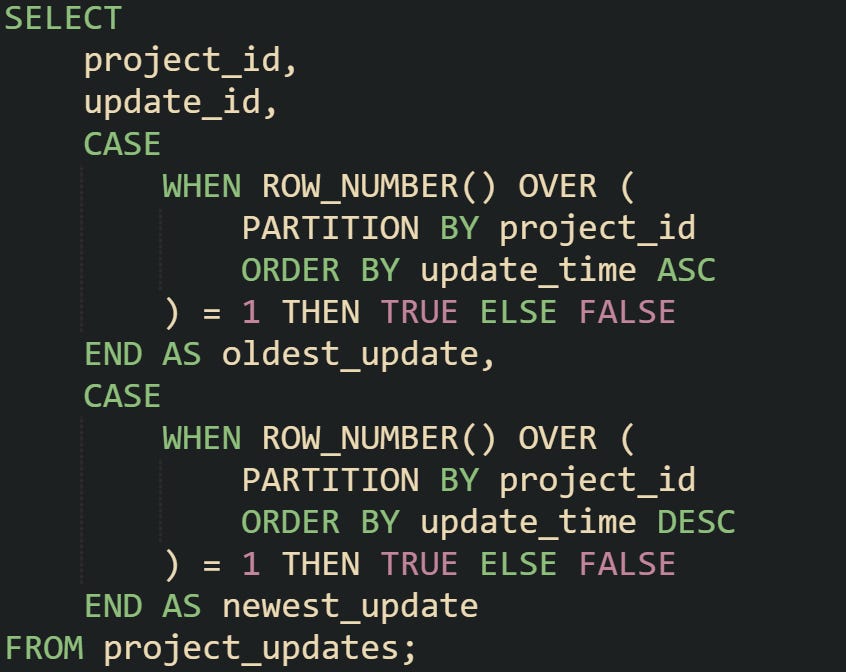
That version returns both flags, which can be useful in audit logs or activity feeds where you want to tag the beginning and most recent records without filtering away the rest.
Aggregate Functions With Window Frames
In some situations it’s more efficient to compare rows against aggregate values like MIN() or MAX() instead of assigning sequence numbers. Window functions allow these aggregates to be calculated per partition, giving every row access to the values for its group.
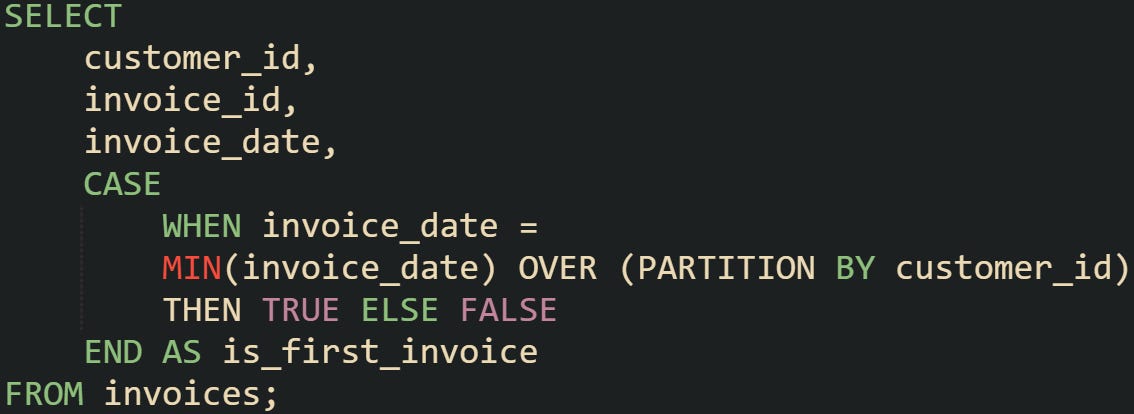
Every row for a customer gets the earliest invoice date for that customer attached to it. Only the row where the dates match is flagged. That makes it easy to query for the first invoice without needing to filter or rank across the whole table. You can extend this pattern by comparing multiple columns. A common case is when the timestamp may be the same, and a tie-breaker column is needed.
Filtering With QUALIFY In Modern Databases
Some systems extend SQL with the QUALIFY clause, which lets you filter rows based on the result of window functions without wrapping the logic in subqueries. This can make queries shorter and easier to read when you only want the flagged rows returned instead of every row with a flag.
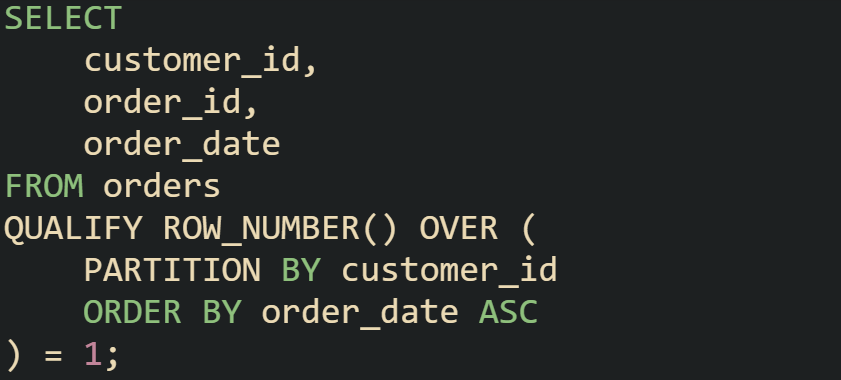
That statement directly filters for the earliest order per customer. There’s no need for a separate subquery or CTE. It’s available in Snowflake, BigQuery, Teradata, and Amazon Redshift, many other engines don’t have QUALIFY.
In some cases you can also combine QUALIFY with RANK() or DENSE_RANK() to fetch multiple rows that tie for the same position. For example, pulling all customers who placed their very first order on the same date.

The result in that case includes every first order even when multiple share the same timestamp. This pattern is handy for business rules that treat ties as equally important.
Adding Flags In Reporting Queries
When reports need both detail and positional context, the query that adds flags is often wrapped in a view or a common table expression. This way, the logic stays separate but can still be reused in multiple reports or downstream joins.
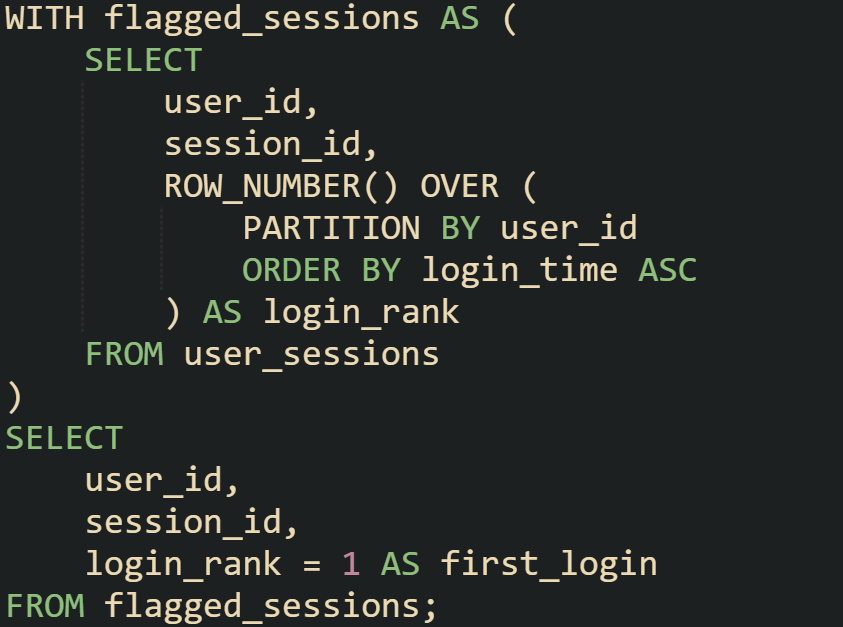
The CTE holds the ranking, and the outer query transforms it into a flag. Keeping the steps separated helps maintain readability when reports grow more complex.
Flags can also be stored directly in a view, making them appear as if they’re native columns. That way, analysts and applications don’t need to repeat the ranking logic every time they query the table. A view definition like this can serve as a single source of truth.
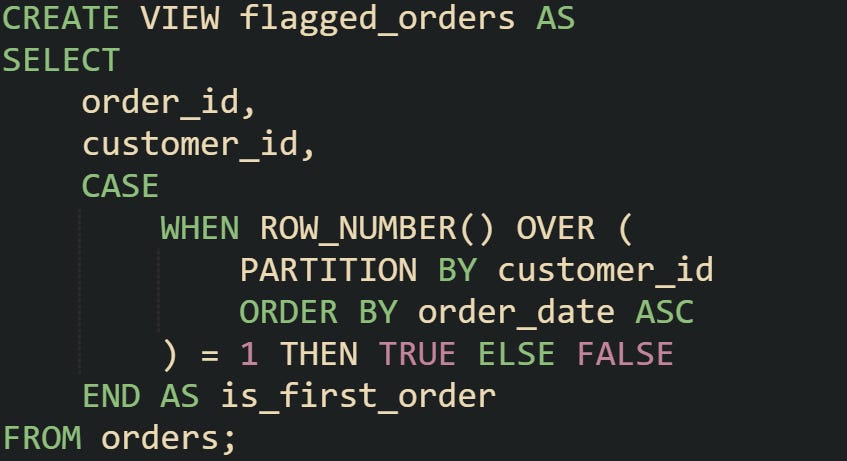
With the view in place, any query against flagged_orders can access the flag without embedding the logic again. This reduces clutter and gives consistent results across multiple reporting needs.
Conclusion
Adding flags for first or last rows comes down to how databases order records, divide them into groups, and assign position with ranking or aggregate functions. The mechanics that drive these features let SQL queries carry more context directly in their results, cutting down on extra steps and giving a structured view of data that would otherwise be unordered.

{kind=link}