

Breaking Big Queries into Manageable Parts with CTEs
Use CTEs to organize your SQL without nesting everything


{kind=link}
When a query gets too long, it becomes harder to follow, debug, and adjust. A Common Table Expression (CTE) is a feature supported by most modern SQL engines that lets you break your query into smaller, readable chunks using the WITH keyword. These chunks behave like temporary views. You can use them to make queries easier to read, layer complex logic step-by-step, and avoid repeating the same logic in different parts of a single query.
What CTEs Actually Do Behind the Scenes
If you write a query using a WITH block, you're creating a named chunk of logic that can be used in the rest of the query. It behaves like a temporary view, but it doesn't stick around after the query runs. This structure helps break down logic into parts that are easier to follow. Behind the scenes, the database treats these parts more like planning hints than objects you can interact with directly. What happens during execution is more mechanical than many people realize.
CTEs are used because they give structure, but how the database processes them is different from how you might expect if you’re used to regular views or temporary tables.
They Are Not Stored Objects
A Common Table Expression looks like it should behave like a table, but nothing is stored. You can’t query a CTE later or reference it in another query outside the current statement. The WITH block just wraps a named subquery. The only place you can use it is within the same query that defines it.
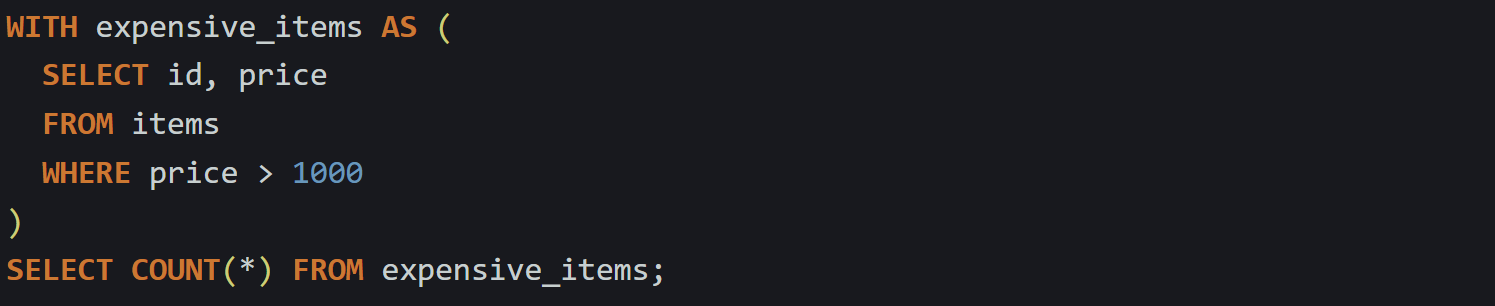
Here’s a quick example to show that nothing is persisted:

The name top_customers is just a label the planner uses. It doesn't turn into a temp table behind the scenes. If you try to query top_customers in a different statement, you'll get an error. This is part of what makes CTEs useful. They exist just long enough to be compiled into the query plan. You don’t have to clean them up or manage their memory. The database knows they’re temporary and processes them accordingly.
Inline Substitution at Planning Time
Once the query reaches the planner, the CTE gets swapped in where it’s used. It’s like a macro being expanded before the database runs the actual query. That means the logic inside the CTE is treated exactly the same as if you’d pasted the entire subquery directly into the spot where the CTE is used.
The planner looks at the structure of the query, reads the WITH block, and substitutes the named CTEs directly into the main query tree before building an execution plan.
The planner rewrites this mentally as:

The database doesn’t run the CTE first, store its results, and then use them in the next step. Instead, it merges the logic into the query plan and treats it like any other part of the structure. This gives the planner full control over how to order steps, combine filters, and push down predicates if possible.
In the past, some systems treated CTEs as isolated blocks that always had to run first. That changed because it made performance worse. Modern PostgreSQL, for instance, started inlining CTEs by default in version 12. You can still force the old behavior with the MATERIALIZED keyword, but it’s not the default anymore.

Adding MATERIALIZED tells the engine to treat the CTE as a fixed result. It builds that result first, saves it in memory, and only then continues. That can help when you need to reference the same logic more than once without re-running the filters or joins inside.
Multiple CTEs in One Block
You can define several CTEs inside a single WITH clause. They’re separated by commas, and you can use earlier ones inside the definitions of later ones. The planner processes them in order. Each one gets compiled as the next CTE reads it, and all of them are part of the same planning context.
Here’s an example that builds a two-step process for working with transactions:

This structure works because account_summaries can reference filtered_transactions. You don’t have to wrap each step inside a nested subquery. Instead, you give each part a name and keep your logic flat. Behind the scenes, both CTEs are just parts of the final query tree. Nothing gets stored or separated. The planner assembles the logic from top to bottom and builds a single plan that includes all of it.
This is handy when each step transforms the data in a meaningful way. You could start with a filter, then apply a grouping or a window function, then join that with another dataset. Each transformation gets its own CTE, and the final step just reads from those pieces. It’s clear, and it’s efficient because the database compiles it all at once.
Structuring Complex Queries Using CTEs
When queries grow in size and complexity, they often end up with deeply nested subqueries that are hard to manage. It’s easy to lose track of what’s happening where. CTEs give you a way to write each logical step on its own line, label it with a name, and then use it like a temporary building block. That can make it easier to reason through what the query is doing and change parts without unpacking several layers of nesting. The structure stays flat, and the logic is easier to adjust without breaking the whole thing apart.
Layering Instead of Nesting
Nested subqueries get dense fast. You’ll often find a large query where one SELECT is buried inside another, which is buried inside a third. It works, but it’s hard to follow. Using a CTE, you can take each of those steps and pull them out into named blocks. Instead of reading from the inside out, you move from top to bottom.
Take a situation where you’re filtering data, doing an aggregation, and then joining with another table. Here’s how that looks when you stack everything inline:
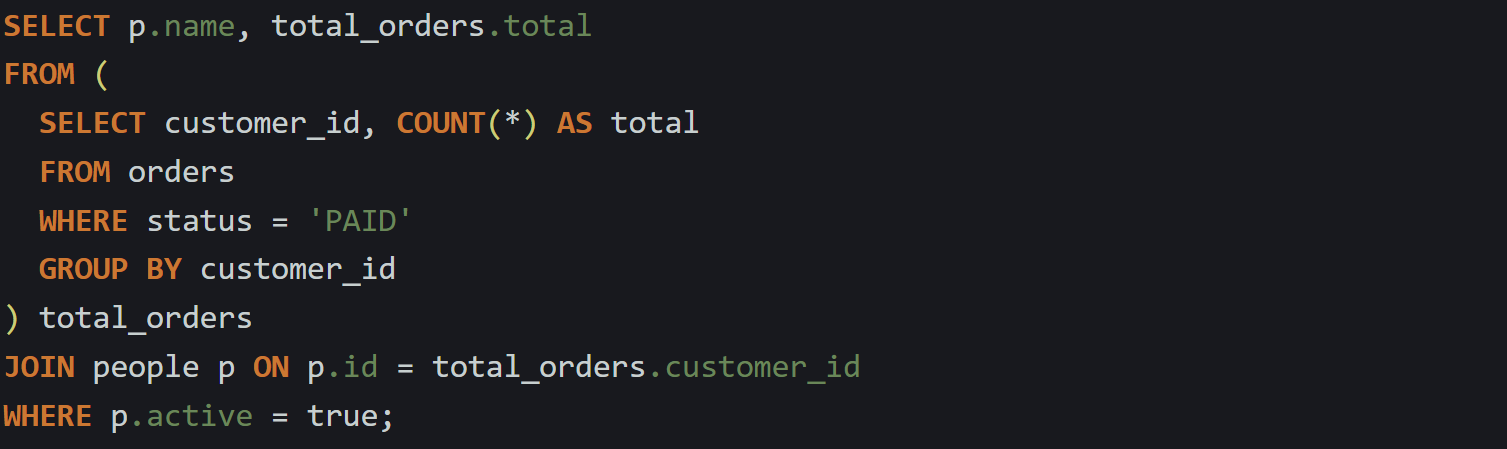
Now compare that with a CTE version:
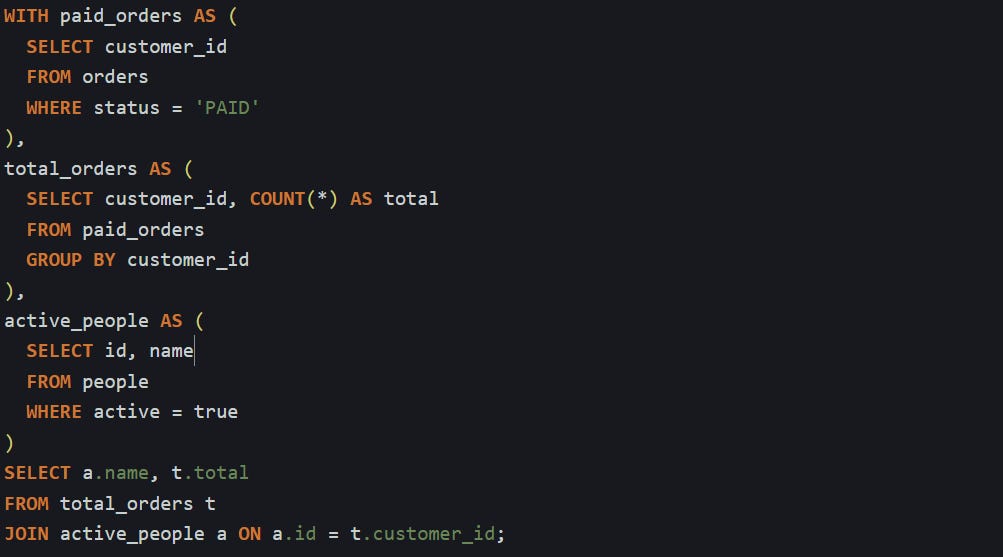
The logic doesn’t change. You still get the count of paid orders for each customer, filtered to only include active ones. What’s different is how easy it is to read. Each step lives on its own and has a short name. That makes it easier to find the exact part of the logic you want to tweak.
You can also cut or reorder steps without touching other parts of the query. With nested queries, it’s hard to lift out just one layer. With CTEs, each layer is already separate.
Reuse in the Same Query
If you filter or calculate something and need to use that result more than once in the same query, writing a CTE makes that cleaner. You don’t have to copy and paste the same logic twice. That saves effort, but it also helps avoid mistakes that happen when the logic gets updated in one place and not the other.
Suppose you’re working with a set of logs and need both the total number of logs above a certain severity level and the number of unique users that triggered those logs. You can do it like this:

The filter on severity only appears once. That keeps the logic tight and avoids cluttering the query with repeated sections. You’re also making it easier to change the severity level later. If that filter was buried in two different subqueries, it’d be harder to find and update consistently. Some databases will re-run the CTE logic if it’s used more than once. Others will optimize it into a shared result. Either way, the clarity you gain by writing the logic once is usually worth it.
Using Recursive CTEs For Hierarchies
Sometimes your data has a parent-child relationship that goes beyond one level. That could be a company’s org chart, a folder structure, or any case where records point back to other records of the same type. Recursive CTEs handle these cases by using the CTE name inside its own definition. It works by combining a base case with a step that refers to the growing result.
Say you’ve got a table of employees with id, name, and manager_id. You want to find every person who reports to a specific manager, directly or indirectly. Here’s how a recursive CTE could look:
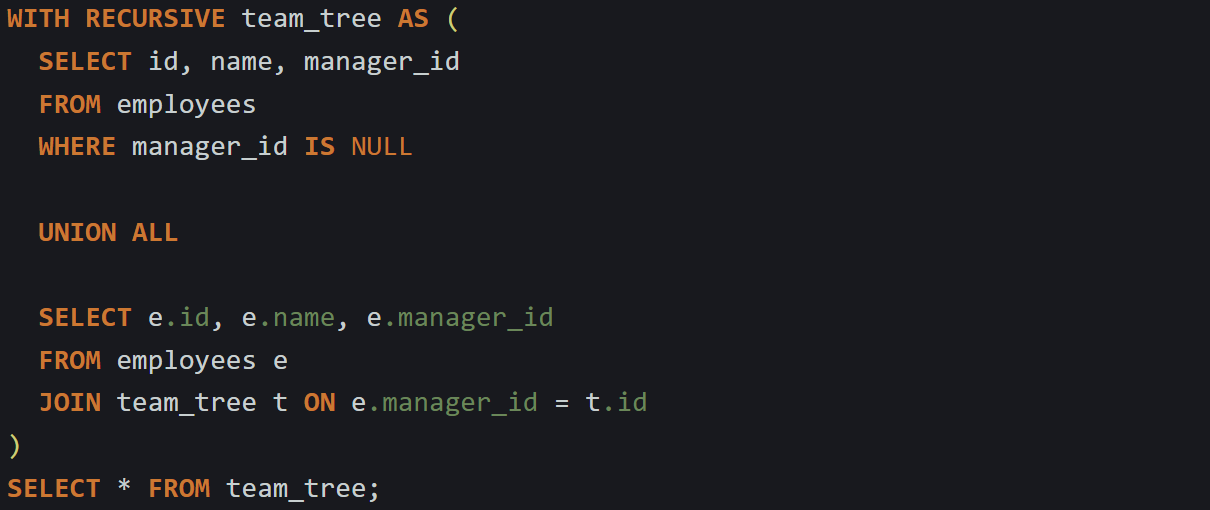
This starts with employees at the top of the org chart, where manager_id is null. Then it walks down the tree, joining each employee to their manager and repeating the process. The engine keeps expanding the result until no more child records are found.
You can also filter it to start with a specific manager:
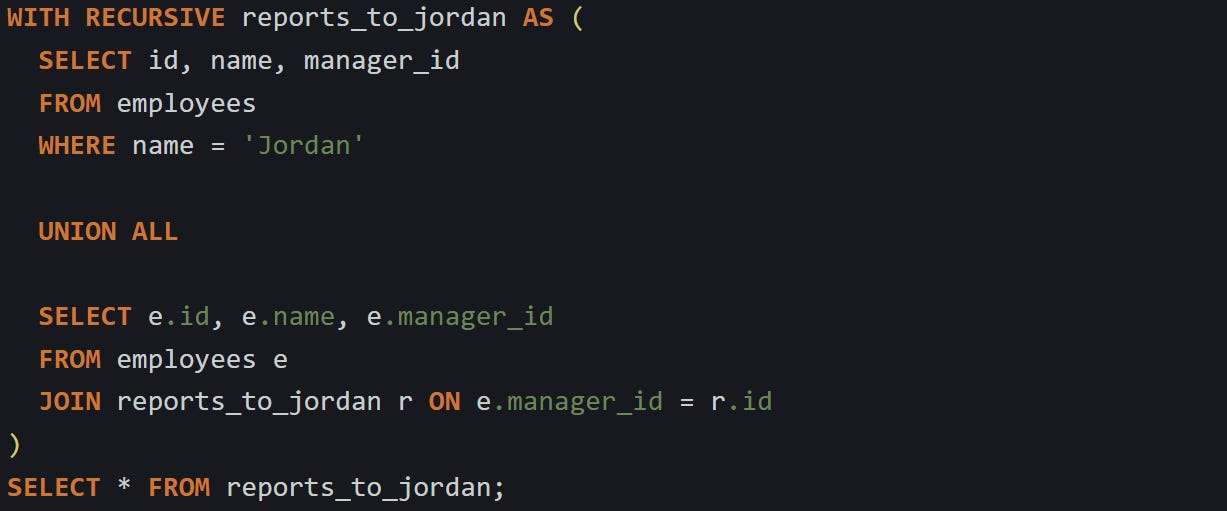
Recursive CTEs give you a way to describe repetition declaratively. There’s no loop keyword, but the behavior is similar. The planner knows to keep applying the recursive step until nothing new gets added.
When A Subquery Might Be Better
CTEs are good when your logic builds step-by-step or when you’re reusing the same part more than once. But not every filter or transformation needs its own name. If the logic is short and only used once, keeping it inline may be more direct.
Take a single filter like this:

Pulling the EXISTS check into a CTE just for the sake of naming it would add more text than it saves. It’s better to use a CTE when it makes the structure clearer or when it avoids repeating the same logic in multiple places.
There’s a balance between clarity and overhead. When the steps get longer or when the logic branches, CTEs help make it more readable. When it’s just a single short subquery, staying inline can be easier to scan.
Conclusion
CTEs work by letting you write each part of a query in steps the planner can stitch together during optimization. Nothing is stored, and nothing runs ahead of time unless you force it. Each WITH block becomes part of the query tree, so filters and joins behave just like they would if you’d written them inline. When you need to reuse logic or build it out piece by piece, they give you a clean way to do that without nesting everything inside itself. Recursive ones go further by letting you describe self-repeating steps without loops or procedural code. It’s all still one query, just better organized.