

Applications may depend on scheduled or background jobs to handle data processing, send out notifications, or perform system maintenance. Within distributed Spring Boot services, it becomes important to keep control over how these jobs are triggered so multiple copies of the same job don’t overlap. Without that coordination, you could end up with the same job running at the same time across different instances, which creates duplicate work or leads to conflicts.
How Concurrent Jobs Are Scheduled and Controlled
Controlling concurrency in Spring Boot begins with understanding how jobs are scheduled, how they behave within a single service instance, and what changes once several instances are active. The mechanics cover everything from Spring’s thread management to external systems like databases or caches that coordinate across a cluster. The guiding principle is that a job shouldn’t start until there’s confidence no other of the same kind is already running.
Spring Task Execution Model
Spring provides built-in scheduling through the @Scheduled annotation, which relies on a thread pool executor. With the default configuration, there’s only one thread available, so jobs never overlap. As soon as you raise the pool size, the scheduler can run several jobs in parallel. That flexibility is useful for different workloads but also opens the door to overlapping runs of the same job.
A minimal example looks like this:

This setup relies on the single-thread pool, which guarantees only one scheduled job runs at a time. If you decide to expand the pool, concurrency management becomes necessary.
To adjust the pool size, you can declare a scheduler bean in configuration:

Local Concurrency Control with Annotations
When you expand the thread pool, Spring won’t stop a scheduled job from overlapping with itself. To add control at the local level, many teams turn to Quartz Scheduler. Quartz integrates neatly with Spring Boot and lets you mark a job detail with @DisallowConcurrentExecution, which prevents concurrent runs of the same JobDetail (same JobKey) across the scheduler or a cluster.

If the trigger fires while the job is still active, Quartz waits until the current run finishes before starting a new one. That behavior works well when you’re dealing with a single application instance.
It’s also possible to handle this without Quartz by adding your own safeguards. Atomic flags or reentrant locks can be used directly inside a Spring component.

This lightweight guard works within a single JVM. While it doesn’t extend across multiple service instances, it keeps local overlaps from happening.
Cluster Wide Locking Mechanisms
As soon as an application runs on multiple nodes, local controls aren’t enough. Each instance has its own memory, so flags and locks inside one JVM don’t affect another. To prevent jobs from running at the same time across the cluster, you need a shared coordination system. Distributed locks provide that coordination. They use an external store such as Redis, ZooKeeper, or Consul so that only one node can claim the right to run a job. Redis is often used for this purpose because it offers strong support for distributed locking with libraries like Redisson.

This structure makes sure only one node holds the lock, and the timeout prevents a deadlock if the process holding it crashes.
For anyone using ZooKeeper or Consul, ephemeral sessions can be used instead. These sessions disappear automatically if the node goes down, which naturally frees the lock without manual cleanup. That extra reliability is helpful in clusters where node failures are expected.
Job State Tracking in Databases
Another option is to manage job concurrency through a relational database. The idea is simple, keep a table that records which jobs are running. Before a job starts, it writes a record into the table. If that record already exists, new runs are blocked. Once the job finishes, the record is removed.
Table definition:

A Spring service can interact with the table through transactional inserts or updates. Database constraints such as primary keys or unique indexes enforce exclusivity.

With this, only one instance of the job can claim the lock row. All other attempts fail until the row is released. This method doesn’t require an extra system like Redis, which makes it attractive for teams already committed to relational databases. The trade-off is the extra load placed on the database, which means it works best when the number of scheduled jobs is moderate.
Preventing Multiple Jobs From Running
After setting up the basics of scheduling, the next challenge is making sure a job doesn’t run more than once at the same time. That can mean stopping overlap inside a single service or coordinating across several nodes in a cluster. Spring Boot offers different ways to handle both cases, and the right choice depends on the environment you’re running in.
Using Quartz Scheduler in Spring Boot
Quartz is widely used with Spring Boot because it gives strong control over job execution. The @DisallowConcurrentExecution marker prevents a job from starting if a previous run is still active. Beyond that, Quartz can run in clustered mode, where each node checks a shared database before starting a job. That shared state keeps different nodes from triggering the same work at once.
Clustered mode relies on JDBC storage:
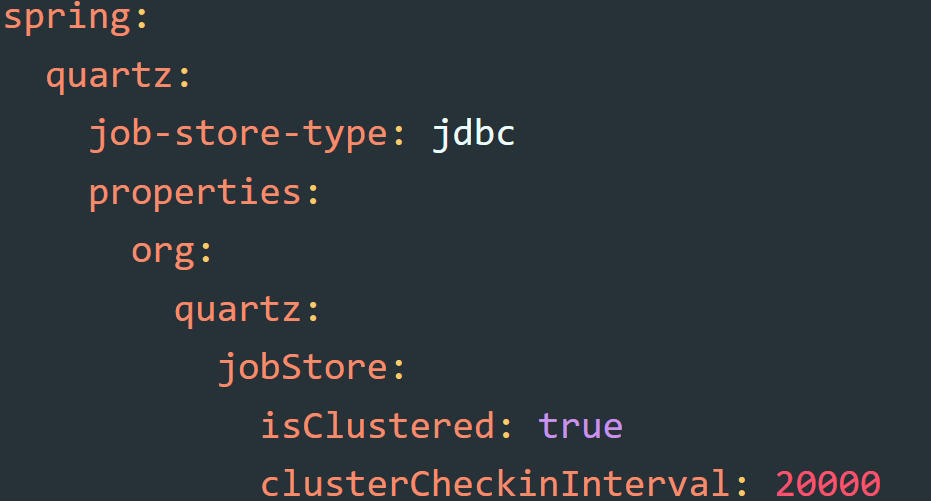
With this configuration, Quartz writes triggers, job data, and lock details into the database. Only one node runs the job at any given moment, while the others wait their turn. That behavior is valuable in scaling environments where new nodes come online and need to coordinate with existing ones.
Distributed Locking Libraries
Some teams prefer to keep Spring’s @Scheduled and add concurrency control through distributed locks. ShedLock is designed for this exact need. It stores lock information in a database, Redis, or another shared system so when one node starts a job, the others skip their turn until the lock is released.
Example with ShedLock:

The lockAtMostFor field makes sure that the lock isn’t held forever if something goes wrong, while lockAtLeastFor enforces a minimum hold time. That way, you avoid jobs running too quickly back-to-back.
Trade Offs and Reliability
Each method carries strengths and costs. Quartz offers a full scheduling framework with cluster awareness, but it adds more setup and relies heavily on a database. ShedLock is easier to drop into a Spring Boot service that already uses @Scheduled, though it has fewer scheduling features. Redis locks deliver speed and precise control, but they bring another dependency to your infrastructure. Quartz’s database storage can add overhead when jobs are frequent, but it pays off when you need advanced triggers or job chains. ShedLock works well for everyday periodic jobs where overlap prevention is the main need. Redis is a good choice when your environment already runs Redis for other features, making it a natural place to store locks. In every case, the principle is the same because before a job starts it must claim a unique lock or marker that proves no other instance is already running.
Conclusion
Controlling concurrent jobs in Spring Boot comes down to how locks and state are managed before any work begins. At the local level, Spring’s scheduler and Quartz can stop overlaps within a single instance. Across clusters, distributed locks with Redis, ShedLock, or database tables extend that control so only one node can run a job at a time. Each method relies on the same mechanical idea that exclusive rights must be claimed first before execution starts. With that safeguard in place, jobs run without stepping on each other and systems stay predictable under load.
