File Streaming in Spring Boot Without Holding Memory
Send large files from disk or S3 without loading everything into memory


Large file transfers can put pressure on memory fast. Loading everything into RAM at once just isn’t practical when the file gets big. Streaming gives you a way around that by reading the file a little at a time and passing it straight into the response as it goes. That keeps memory usage low and steady no matter how large the file is. You can stream videos, log archives, or exported data straight from disk or remote storage without needing to hold the whole thing in memory.
Streaming Mechanics in Spring Boot
Streaming large files through a Spring Boot application works because the servlet container gives you a direct output stream that writes to the client as data is read. Nothing has to sit in memory the whole time. When the response starts, chunks of data go out bit by bit. This keeps things efficient and lets you send huge files without running into memory problems. The way Spring Boot handles this is mostly transparent, but it helps to understand how everything fits together before writing the actual code.
Servlet Containers Handle Response Streams as Output Pipes
When a request reaches your controller, it passes through the servlet container, typically Tomcat or Jetty, depending on what your Spring Boot app is running on. Each of these servers creates an HttpServletResponse object tied directly to the client connection. That object includes a raw OutputStream that acts like a live pipe.
Writing to that stream pushes bytes to the network connection right away. There’s no need to gather the entire file in advance or store it somewhere temporarily. It flows from your server to the client as fast as the stream allows.
Here’s how that output stream fits into a controller method:

That stream is live. The moment you write to it, data starts leaving the server and heading to the client. If the connection drops halfway through, the server will stop sending more bytes automatically.
Streaming Works Because of How Java IO Reads and Writes in Chunks
Java handles file input through streams as well, and the basic I/O classes are designed to read data in small pieces. This allows you to move data between streams without putting too much into memory at once. You’re not forced to load a file completely to send it over the network. Instead, you open a stream to the file, read it chunk by chunk, and write it to the servlet response output stream just as it’s read.
The key idea here is buffered reading and writing. You set up a loop that reads a fixed-size array of bytes from the input stream, then passes that chunk into the output. This pattern stays consistent no matter how large the file is.
Here’s a closer look:
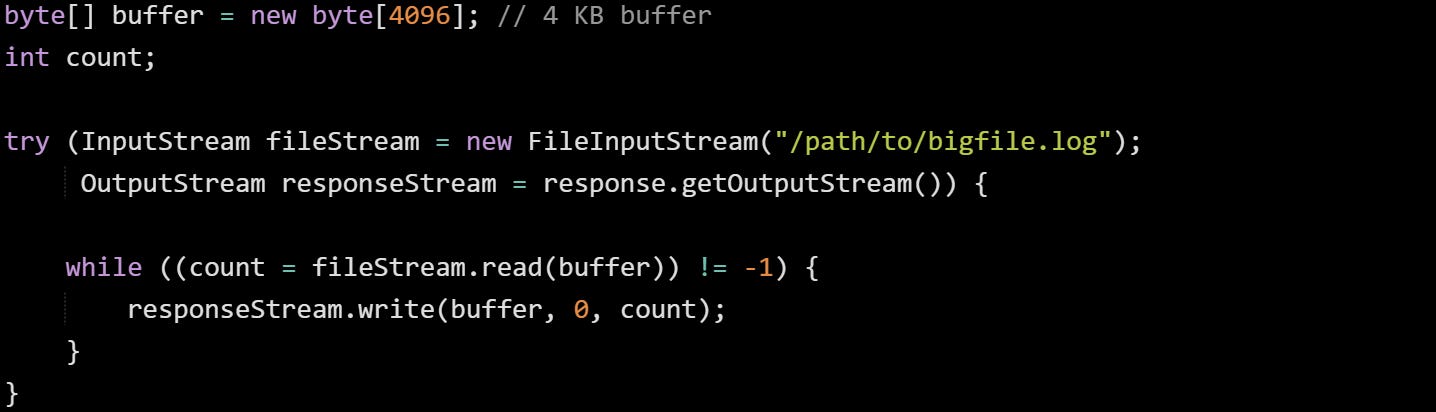
The size of the buffer doesn’t need to be large. A few kilobytes at a time is usually enough. That loop keeps the memory footprint stable and low. You’ll use the same memory block over and over instead of growing memory usage with each new read.
Spring Boot Leaves the Streaming Control to You
Spring Boot doesn’t force you to go through layers of abstraction when you want to stream a response. If you return a byte[] or String in a ResponseEntity, Spring builds the whole body in memory first. But if you return a StreamingResponseBody or a Resource like InputStreamResource, it streams the data instead. You don’t need to rely on those return types though. If you inject HttpServletResponse into your controller method, you're fully in charge of the output and can write directly to the stream. Spring won’t get in the way or buffer anything unless you’ve configured something that changes that behavior.
You can also set headers or tweak the response manually before writing to the output. That includes setting the content type, content length, and attachment disposition.
Here’s another example, just to show how flexible it can be:
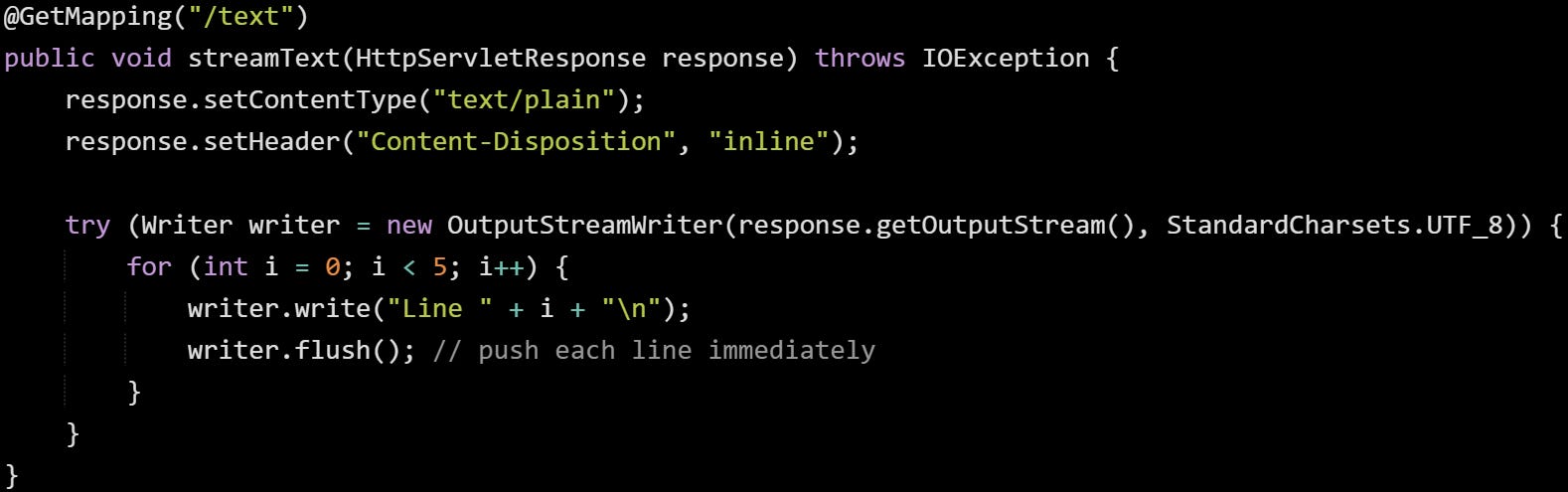
This sends plain text to the client one line at a time. Calling flush() helps push data out quickly, though the servlet container will also flush it on its own when needed. In a real-world case, this might be log data, a stream of progress updates, or a tailing export.
Content Length vs Transfer Encoding
There are two ways the server tells the client how much data to expect. One is by setting the Content-Length header. The other is by using chunked transfer encoding, where the server sends the data in pieces without stating the total size ahead of time. If you already know how big the file is, then setting Content-Length is a better fit. The client will wait for exactly that number of bytes and can show a progress bar if it wants. If the total size isn’t known, or if the stream is generated dynamically, Spring Boot and the servlet container will fall back to chunked encoding.
Here’s how you can set Content-Length yourself:

With this header in place, the client knows how much data it’s about to get, and buffering at the network layer can work more efficiently. If you leave that out, the servlet container will default to chunked transfer, which also works fine but behaves a little differently on the receiving side.
It’s worth pointing out that some clients, like older browsers or custom scripts, may behave differently depending on how the content is delivered. Setting the length when possible gives you more predictable behavior.
Writing a Streaming Endpoint
When you’ve got a handle on how streaming works under the surface, the next step is building an endpoint that actually does it. Spring Boot gives you access to everything you need through the HttpServletResponse. The rest is mostly about wiring up a reliable file read and writing the data out without holding it in memory. You can stream local files just as easily as remote ones, and the setup doesn’t need much code, as long as you stick to small, controlled read and write chunks.
Example Of Direct File Streaming
A local file on disk can be streamed through a controller method with just a few lines. The idea is to open an input stream to the file, read fixed-size buffers, and write those directly into the response’s output stream. You set the headers first so the client knows what to expect, and then begin the transfer.
Here’s a basic version that does this safely and clearly:
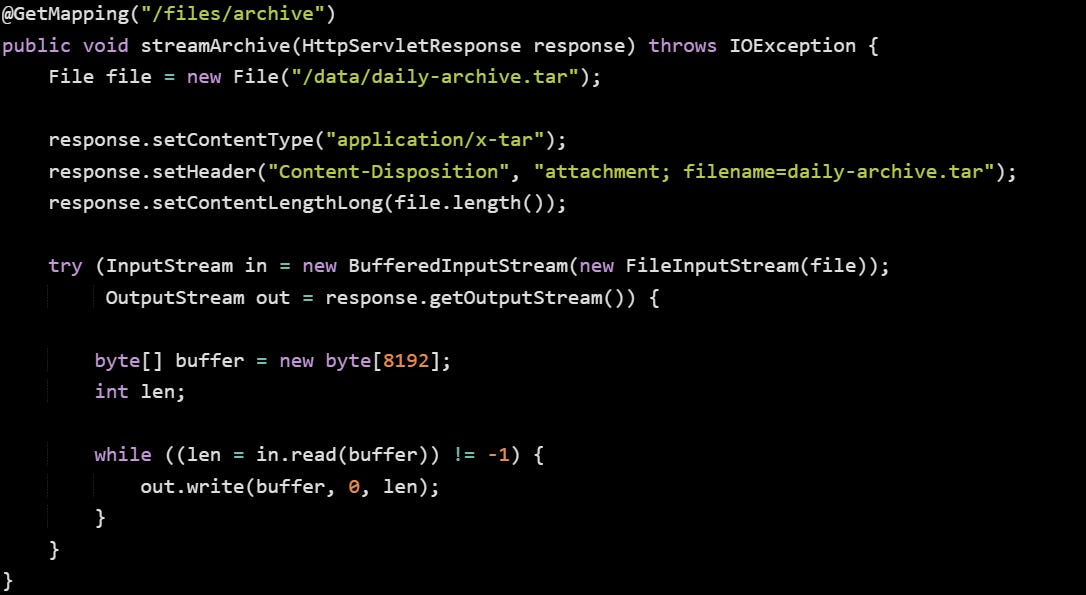
This reads the file from disk in 8 KB chunks, and each one goes straight out to the client. The response stream writes out exactly what the input stream reads in, with no pause to collect everything first. Buffered reading helps reduce disk access overhead, especially on slower storage.
If you know the file’s size, you can call setContentLengthLong() so the browser or client script can show a progress indicator. That part’s optional but helpful when the file is large and you want the download to behave more predictably.
Streaming Files From Remote Storage Or S3
Streaming doesn’t just apply to files sitting on your machine. If your data lives in cloud storage like Amazon S3, you can pull it directly into the response stream. The logic stays mostly the same. Instead of reading from a file path, you get a stream from the S3 client.
Here’s how that looks with the AWS SDK v1:
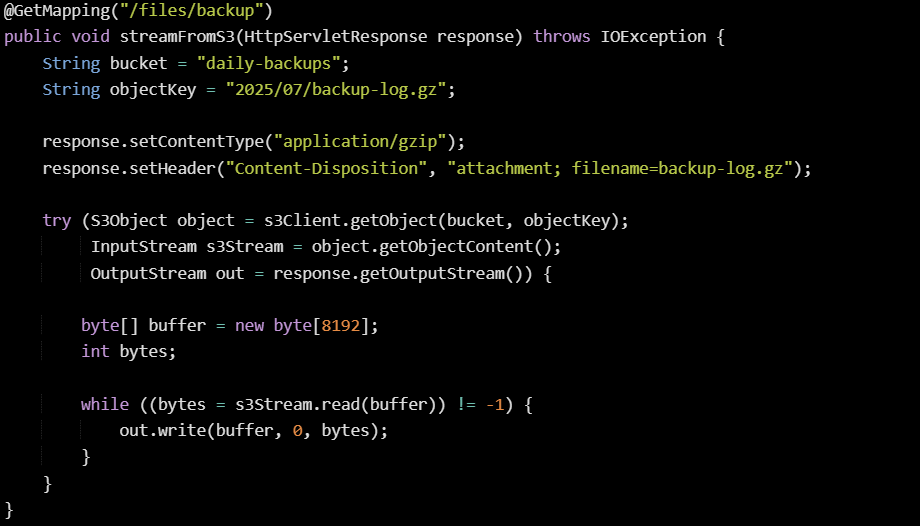
This lets you send files directly from cloud storage without needing to download them to a local temp directory first. The input stream reads from the network, and the output stream writes back to the HTTP client, passing through your server just as a middle layer. Memory stays flat, and performance depends mostly on the source’s speed and the client’s connection.
If your S3 files are large, that streaming loop keeps the memory stable no matter how many people are downloading at the same time.
Avoiding Common Mistakes
Streaming looks easy at a glance, but a few small changes can throw the whole thing off. One of the most common issues is reading the full file into memory before writing it. That happens when developers try to use helper methods like Files.readAllBytes() or wrap the file in a ByteArrayResource.
Another mistake is using ByteArrayOutputStream to build the file in memory first, then writing it out. That’s useful for some edge cases where you need to build up content dynamically, but it breaks down fast when the size grows past a few megabytes. Also avoid any sort of logging or debugging that reads the full content into memory. Dumping a large payload into the logs can cause performance hits or trigger out-of-memory errors even before the stream reaches the client.
If your stream depends on a temporary file that gets deleted before the transfer finishes, that will also interrupt the download. Always keep the source open for the full life of the stream and use try-with-resources so cleanup happens only after you’re done writing.
And when working with S3, avoid .getObjectAsString() or anything that reads the whole file to memory. Always go for .getObjectContent() which returns a stream instead.
Handling Errors During A Stream
Errors during a stream don’t behave the same as normal controller responses. If the response has already started, there’s no way to switch to an error status or return a different content type. This means the best you can do is catch the exception, log it clearly, and close the stream so it stops writing.
Here’s one way to handle it defensively:
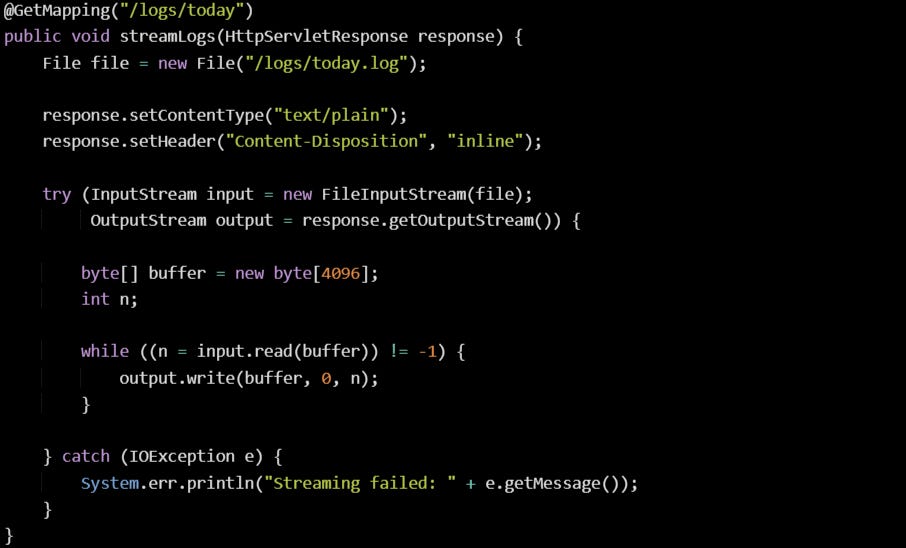
At this point, if something goes wrong halfway through, the only sign the client might get is a dropped connection. That’s fine. The download will stop, and you’ll have the log entry to investigate what happened.
For more critical cases where failure must be visible to the user, the only safe way is to check all your inputs and preconditions before writing a single byte. After the streaming starts, it’s too late to change your mind or switch formats. A good habit is to always flush the response at intervals if the output is slow. That prevents anything from building up unnecessarily in buffers and also makes sure the client sees data sooner. Just don’t overdo it, calling flush after every tiny write can hurt throughput.
Streaming works well as long as you respect how it behaves differently from regular responses. Writing too early, buffering too much, or waiting to catch exceptions late will always make it harder to control. Keeping the stream narrow and predictable is what makes it reliable.
Conclusion
Streaming works because of how the servlet response ties directly into the HTTP connection. Every chunk you write heads straight to the client without sitting in memory. As long as you keep your reads small and pass the data through without trying to hold it, the system stays predictable. The Java I/O model already does most of the heavy lifting, and Spring Boot leaves the response stream open for you to work with. Whether your source is local or remote, the mechanics stay simple. Stream in, stream out, and let the output take care of itself.
