

Tracking missing records in a dataset is something that shows up more often than people expect. Sometimes you’re dealing with time series where you expect a row for each day or minute. Other times it’s about skipped numeric IDs that should follow a sequence. And in systems that log events or transactions, any missing entry can mean data loss or system bugs. Catching these holes manually is easy with a spreadsheet. But catching them inside a database using SQL is a different challenge. The trick comes down to generating the full set of expected values, then using a join to show what’s missing.
Why Data Gaps Happen and Why You Can’t See Them at First
Most datasets don’t arrive complete and in order. It’s easy to assume your tables reflect everything that happened, but that trust can backfire when you’re looking at logs, sequences, or time-based events. You only catch the problem when something goes missing, like a metric doesn’t line up or a report looks thinner than usual. Gaps hide in plain sight because SQL doesn’t surface what’s absent. It shows what’s there, full stop.
So the first step is to understand how gaps sneak in and why your queries aren’t calling them out for you.
Common Causes of Gaps
Tables that track data on a timed schedule often miss rows when the source is interrupted. A sensor expected to log every 5 minutes can stop reporting if it loses power or network access. When that happens, those rows never arrive. There’s no error message in the database. The records just don’t exist. If you pull counts of rows per hour, things might look fine unless you know exactly how many entries were supposed to be there.
Say you have a table that records temperature readings from a device, and you want to check activity by hour. Your table looks like this:

You run a query like:

This gives you a nice count of how many readings came in per hour. But if the device went offline between 2:00 and 2:30, you’ll just see a lower count for that hour. It won’t tell you which specific 5-minute windows are missing, and it won’t tell you that anything is broken.
Gaps can also appear in numeric sequences. Autoincrement columns like a SERIAL or IDENTITY field seem like they’ll always produce a clean, continuous chain, but they don’t. The database will skip values on rollback or transaction failure, and if someone deletes a row, that ID is gone. This usually doesn’t matter for basic lookups, but it does matter when the IDs are used for tracking or are assumed to represent an exact order of operations.
For example, if you’re storing shipment events and expect to trace the history by event ID, a missing ID might break that trace. Suppose your table is set up like this:

You look at the table and the highest event ID is 5000. Then you run:

The result is 4987. You’ve lost 13 records, or more accurately, 13 IDs were never committed. Unless you cross-reference the expected sequence, you won’t know which IDs are missing or why.
Another situation that creates gaps is when systems track a known progression. For example, a device that sends message logs with a numbered sequence from 1 to 1000. If message 500 never arrives but the rest do, everything appears fine on the surface. Counts will be close to what you expect, but one missing message can mean corrupted results or incomplete processing.
Let’s say you have a message log with this structure:

You check how many logs came from a certain device:

If you expect 1000 and only get 999, that doesn’t tell you which message is gone. A missing entry in the middle of the sequence could indicate an upstream bug, or a network loss that wasn’t retried. SQL won’t show it unless you specifically look for message 500 and notice it’s gone.
Why SQL Doesn’t Show the Problem on Its Own
SQL only works with rows that exist. Every SELECT you run queries the records that were successfully inserted. There’s no default structure filled in behind the scenes. If a row is missing, there’s nothing to pull. You don’t get a placeholder or a blank row. You just get fewer results, and unless you already know what’s missing, it won’t raise any flags.
Try running a query like:

If no row exists for that exact timestamp, SQL returns nothing. No error, no warning. Just an empty result set. That can make tracking problems much harder than it needs to be, especially in systems where you expect one record per interval or per ID in a chain.
Spreadsheets and monitoring dashboards tend to show what’s missing because they usually start from a known full list and mark what didn’t arrive. SQL doesn’t work that way. It shows the data that is present, and it stops there. You have to take the extra step to define what should be there and then compare it yourself.
Say your application stores one summary row per day. You want to check what data exists for the first week of May 2025. You run this:

The result looks fine:
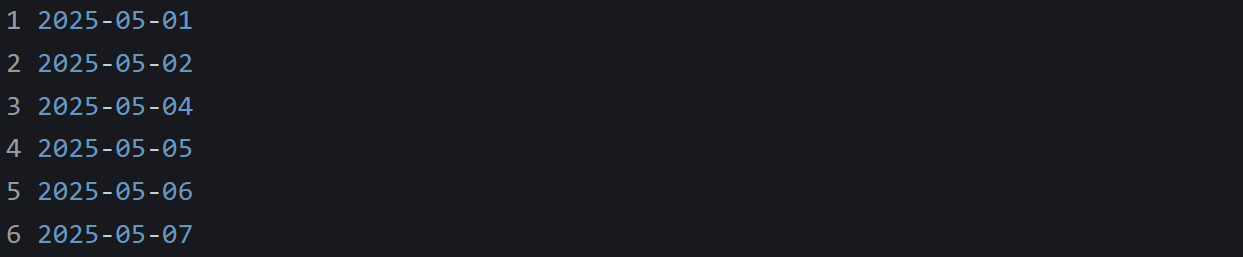
But May 3rd is missing. That might be a data loss issue, a system outage, or just a skipped run. SQL won’t tell you. You only see what was actually saved. Unless you already know every day from May 1 to May 7 should be present, you’ll assume it’s correct. That’s what makes these gaps tricky. Most SQL checks ask “what do we have?” not “what’s missing?” You won’t catch a problem unless you build out the expected values yourself and match them against what came through.
Spotting missing records takes a different mindset. The data won’t announce what’s absent, and the database won’t point it out either. It’s on you to ask for what didn’t happen, not just what did.
How to Detect Missing Rows Using a Clean Join Pattern
Spotting missing data by hand only works when the dataset is small or visual. But once you’re working in SQL with production tables, you need something sharper. There’s a method that works across time-based data, sequential IDs, and combined key values. The idea is to generate the list of values you expect to exist, then run a left join against the real table and filter for anything that didn’t match. It’s not a workaround. It’s a pattern built into how SQL joins behave, and it’s clean and reusable if you know what to ask for.
Detecting Gaps in Time Series Data
Time series data usually comes with a regular pattern, like one row per day, per hour, or per minute. That pattern gives you something to compare against. So you can generate the full list of timestamps you expect, then left join that to your real table and check for missing rows.
If you’re using PostgreSQL, the generate_series function makes this fast. Say you expect a row every day from January 1 to January 31 in 2025. You’d start by building the full range of days like this:

That gives you 31 rows, one for each date. Now you can match that to your actual stats table. Suppose your table looks like this:

Now combine the two like this:

This will return only the dates that didn’t match anything in your real data. In other words, the ones that are missing.
If you’re on MySQL 8.0 or later, you can use a recursive common table expression to do the same thing. It’s a little longer but works just as well. Here’s how you’d build a daily range from January 1 to January 31:
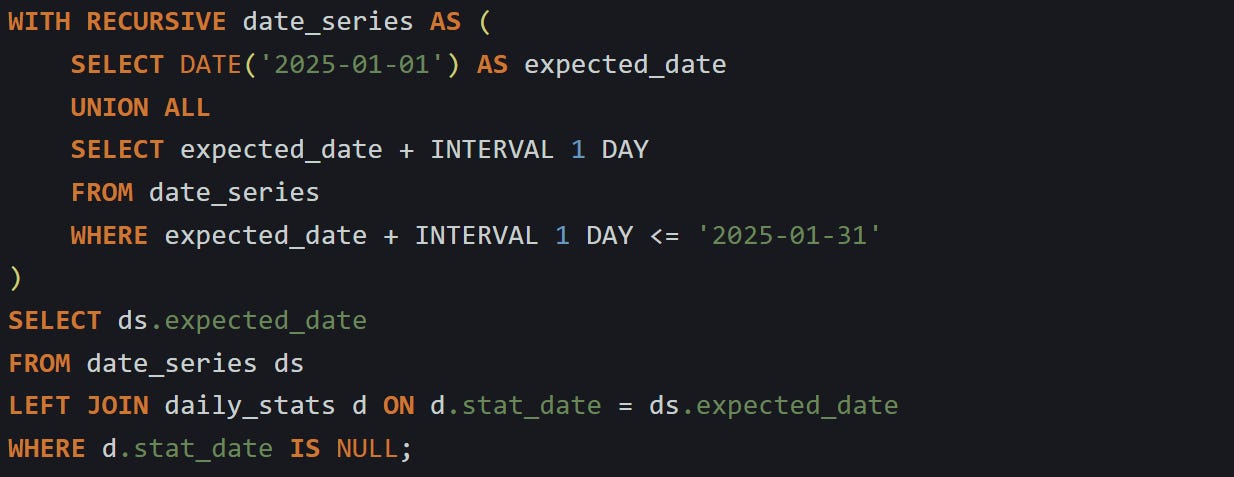
That’s the same pattern. You create the list of what should be there, then use a left join to check which dates were never written to the table. This works for data stored daily, hourly, or even every few seconds. You just adjust the step size in generate_series or INTERVAL. The strength of this method comes from the fact that it doesn't rely on what’s already in the table. It starts fresh with what’s expected, then compares.
Detecting Skipped Numeric IDs
Sometimes you’re not working with time, but with numeric sequences. This happens a lot with IDs, batch numbers, or step counters. If you’re expecting rows numbered 1 through 1000 and 873 is missing, most queries won’t say a word about it. The count will look close enough, but one row is gone.
This can be caught using the same join method. In PostgreSQL, just use generate_series to build the expected IDs:

That gives you every number between 1 and 1000 that has no match in the orders table. Here’s a simple example table:

If rows 47 and 872 are missing, they’ll show up here.
In MySQL, you’d use a recursive CTE again:
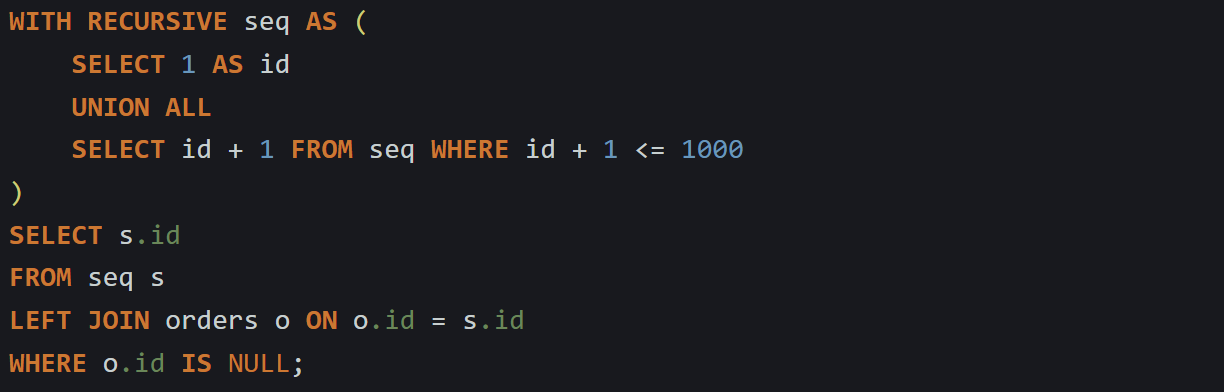
This gives you the same result. Any number that didn’t appear in the real table gets flagged.
The join doesn’t care how the row went missing. Maybe it was deleted. Maybe the insert failed and the ID was consumed anyway. All that matters is that the expected number doesn’t show up in the data.
What Makes the Join Pattern Work Mechanically
This trick depends on how SQL joins work, not on a special feature. A left join includes all rows from the left side of the query, and then tries to match them to the right side. If it can’t find a match, the fields from the right table come back as null. That’s exactly what makes this pattern useful. When you generate the expected values on the left and join them to real data on the right, the nulls point out where the match didn’t happen. That’s your missing entry. So if a date or ID from your expected set has no corresponding row in the actual table, it comes back with nulls and is easy to filter.
Here’s a small example with made-up values to show it plainly:

This would return 2 and 4. Those numbers were expected but didn’t appear in the real data.
The engine builds this join by scanning one side and then trying to match each row to the other. Depending on the database and the indexes, it might build a hash table or scan line by line, but that’s abstracted away. The important thing is that the structure allows for easy spotting of rows with no match.
You don’t need complicated logic or procedural code to make this work. It’s a mechanical property of left joins and nulls. That makes it stable and reliable when the pattern is used correctly.
A Variation for Multi-Column Keys
Sometimes it’s not just a missing date or ID. Some tables depend on combinations of values. A good example is when you expect one row per user per day. You can’t just generate a list of dates. You need to build every pair of (user_id, date) and compare that to what the table actually holds.
Let’s say you want to check which users didn’t log activity for each day in May 2025. First, get your users:

Then build a date series:

Now cross join those to build the full grid:

That gives you every user paired with every day. You can now left join that grid to your activity table:
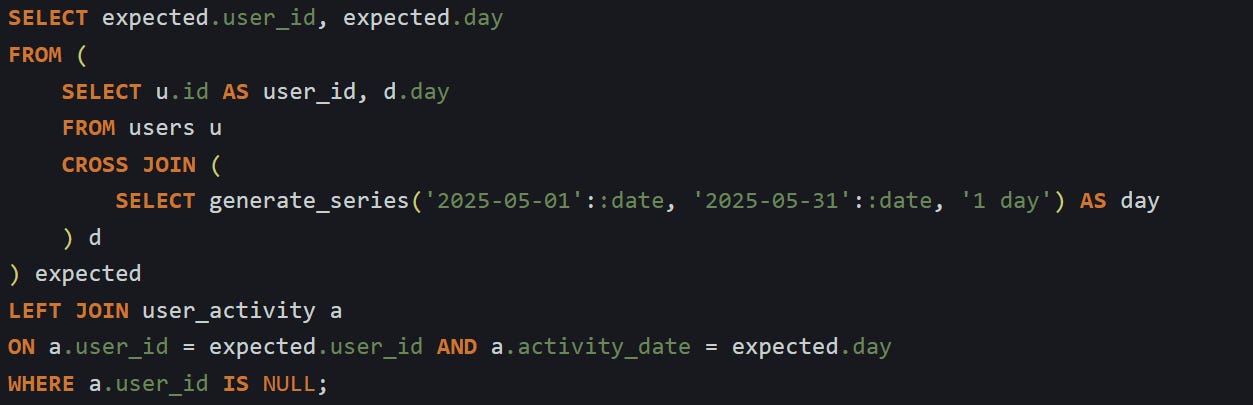
Now you’ll get a list of users and days where there was no activity. It’s the same pattern: build the full set, join to the real data, and find what’s missing. You can apply this to any pair or combination of columns. The only requirement is that you know what the full set is supposed to look like so you can generate it.
Conclusion
SQL doesn’t tell you what’s missing. It only returns what’s there. The join pattern works because of how left joins keep everything from the expected side and fill in blanks where nothing matched. That’s the part that does the heavy lifting. When you build a list of what should exist and line it up next to the real data, those blanks become easy to spot. The method isn’t tied to time series or sequences alone, it holds up wherever you can define the full set and compare.

{kind=link}