

When you work with relational databases, situations often come up where data stored in one table needs to stay in sync with data in another. Applications that split information across multiple tables rely on this kind of consistency, otherwise values can drift apart over time. A reliable way to keep everything aligned is to combine an UPDATE statement with a JOIN. That pattern lets you pull values from a source table and apply them directly to a target table, so both remain consistent without manual fixes.
How an Update with Join Works
When you combine an UPDATE statement with a JOIN, the database is doing more than just replacing values. It’s building a connection between two tables, finding the rows that match based on your condition, and then taking values from the source to overwrite or sync into the target. Different database systems handle the syntax in their own ways, but the concept is consistent.
What Happens During an Update
For most systems, an UPDATE changes rows in one table. MySQL also supports multi-table updates, though the examples here target a single table. The database scans the target table, finds the rows that meet the condition in the WHERE clause, and applies the new value you’ve given it. Without a join, the value is usually static or calculated.
Take this example where every product’s price is raised by 10 percent.

The database doesn’t look outside the Products table. It just takes the existing value and multiplies it.
Now, when you involve another table, the work changes a little. The database must line up rows across tables before it can make the update. Let’s say you have a Products table and a separate PricingAdjustments table that holds updated prices from a supplier.

At this point, the database creates a mapping between Products and PricingAdjustments by comparing product_id. Once those pairs are built, it copies values from the source over to the target. Rows that don’t find a match are left alone.
Internally the database optimizer is choosing how to scan, which indexes to use, and how to match rows efficiently. That’s why an update with a join is far more than a straight overwrite.
The Role of Joins in an Update
Joins are best known from SELECT queries, where they pull together information across tables. Inside an UPDATE, the join serves as the bridge that makes it possible to reach across tables during the modification.
Let’s look at a scenario with employees and departments. Suppose department names are updated in the Departments table, and you need to push the latest names into the Employees table.

The join condition matches employees to departments. Once those links are in place, the update takes values from Departments and moves them into the Employees table. The important point is that Employees is the only table being modified, even though the query touches both.
Sometimes it’s helpful to use multiple conditions in the join. Maybe an employee can belong to more than one department based on region, and you want to make sure you update the right one.

Here the join requires two points of alignment, which narrows down the matches and keeps updates from being applied incorrectly. This flexibility is what makes joins in updates so valuable.
Different SQL Dialects
Every major database system supports updating one table from another, but they don’t all write it the same way. Syntax changes across PostgreSQL, SQL Server, MySQL, and Oracle. The mechanics remain steady, though, so once you know what’s happening in the background, adapting to each system is easier.
In PostgreSQL and SQL Server, the FROM clause is commonly used.

MySQL uses JOIN directly inside the update, which places the source table beside the target from the start.
Oracle leans on subqueries instead of a direct join, which can feel less direct but works the same way.
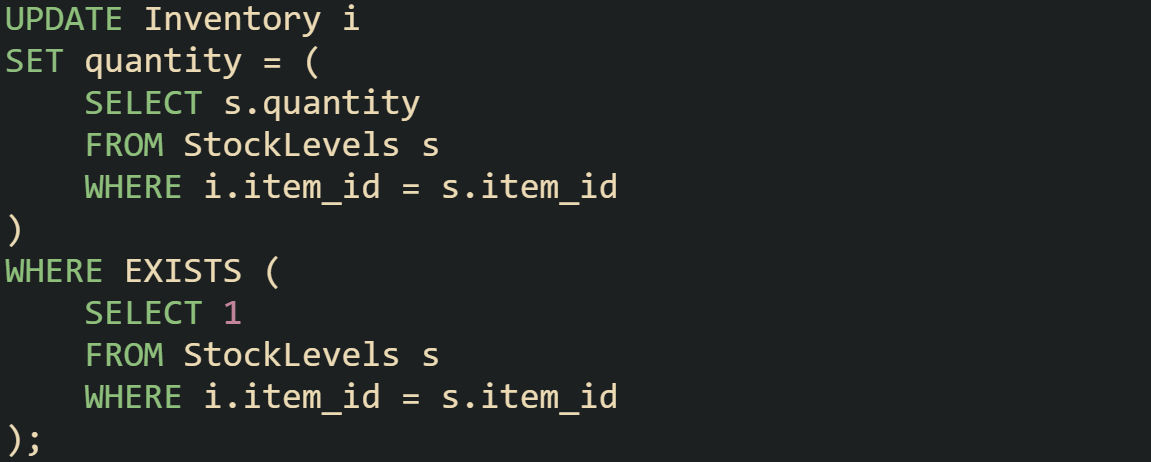
Notice that Oracle needs the EXISTS clause to prevent updates when no matching row is found in the source. That extra condition keeps the database from setting values to null in cases where the join fails.
Different dialects may look different, but under the surface they’re doing the same job: matching rows, picking the right values, and applying them to the target table.
Practical Walkthroughs with Examples
Working with updates that pull data from another table is easier to understand when you see how it plays out in everyday scenarios. The following examples show real patterns that come up often, each with its own mechanics. Seeing them in context helps connect the idea of a join with the update process.
Syncing Customer Data
One of the most common places where this comes up is customer information. Many systems store a master record for customers in one table and duplicate some of that information in another table for faster access or reporting. Over time, these copies can drift out of sync. An update with a join lets you repair that mismatch.

The join matches orders to customers on the shared identifier. When the database has those matches, it updates the address field in Orders with the most recent address from Customers. Sometimes you may need to update more than one field at the same time. If you’re pulling from the same source table, it’s efficient to set them together in the same query.

Now both the phone number and address are refreshed in a single run, which keeps the target consistent in fewer steps.
Overwriting Based on Conditions
Updates don’t always apply to every matching row. It’s common to add conditions that limit which rows actually get changed. This way the database only modifies rows that meet the extra requirements. Suppose you want to update product descriptions in a catalog, but only for items that are still active. The source is a ProductUpdates table that contains new descriptions.

The join still provides the connection, but the added condition in the WHERE clause restricts the updates to products marked as active. Rows that don’t meet the condition are skipped.
You can also base the condition on values in the source. For instance, imagine you only want to apply price updates if the new price is greater than zero.

This prevents mistakes that could overwrite values with invalid numbers. It also shows how the join can work together with other conditions to keep updates safe and precise.
Handling Large Data Sets Safely
When updates affect large numbers of rows, there are practical steps that help control the process. A database can process millions of updates, but running them all in one go can sometimes be risky. Using transactions and checking your work with a SELECT first makes the process more reliable.
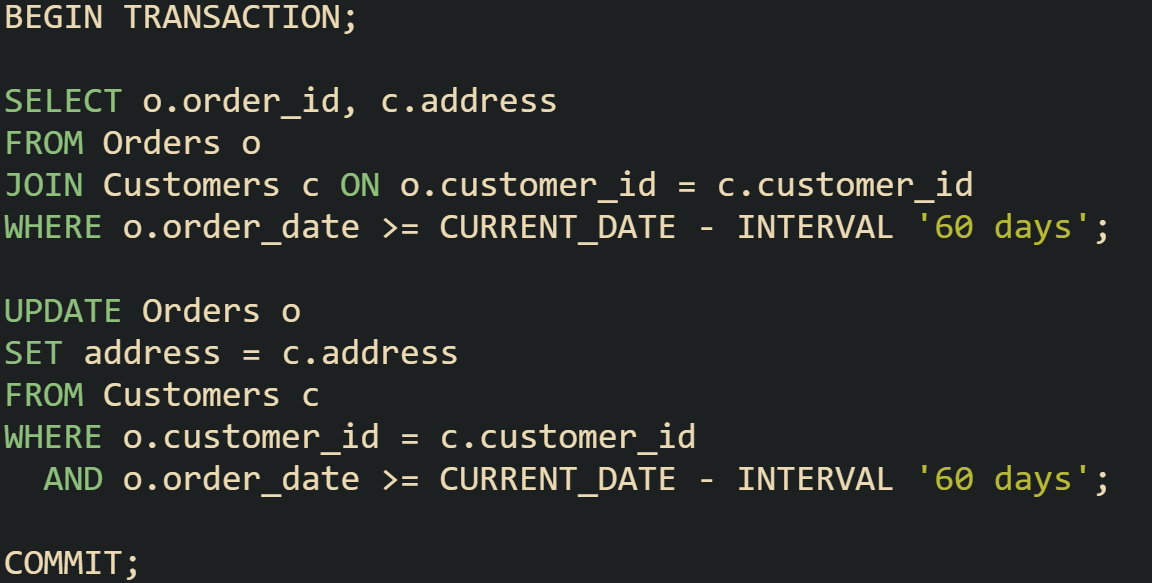
Above the SELECT shows what rows would be affected, letting you review them before running the actual update. If something looks wrong, you can cancel before the COMMIT.
In other cases, batching helps when dealing with very large tables. Rather than updating everything at once, you can do it in smaller ranges.

Running updates in controlled chunks reduces the load on the system and gives you more control if you need to pause or check progress between batches.
How the Database Processes Joins in an Update
When you run an update with a join, the database engine has to figure out the best way to pair rows across the two tables. It looks at indexes, available statistics, and the join condition you’ve written. After it decides on a plan, it runs through the process of matching rows and then applying the update.
If both tables are large, having indexes on the join columns can make a big difference. Without them, the engine may need to scan both tables in full, which can take far longer.
Consider a table of employees and a table of payroll records. You want to copy updated salary values into the payroll table.

The join happens on emp_id. If both tables have indexes on that column, the database can find matches quickly and update the right rows with less work.
Another important thing to consider is what happens when more than one row in the source table matches a row in the target. Different systems handle this in different ways, but it often leads to errors or unexpected results. The safer route is to remove duplicates before the update.
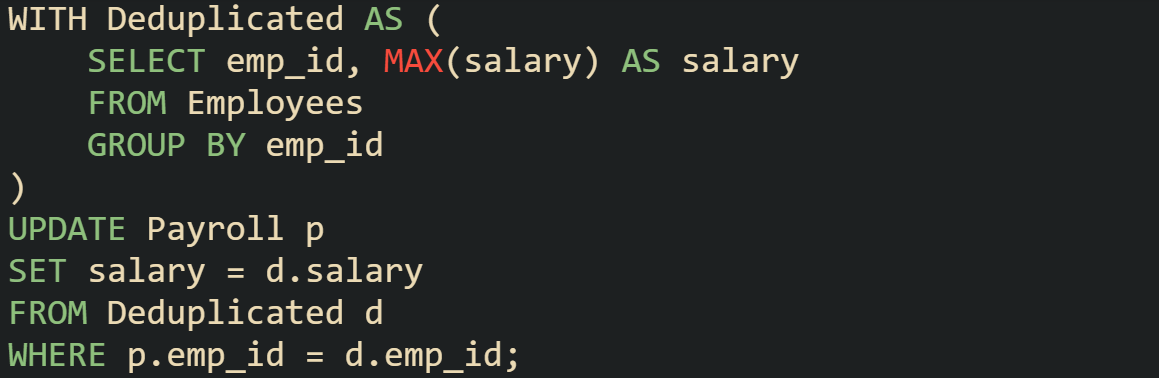
This makes sure each target row has only one matching source row. Without that step, some databases may not know which value to pick, which could leave the update incomplete or incorrect.
Conclusion
Updating one table with data from another comes down to how the database lines up rows through the join and then applies those values to the target. The process starts with matching based on the condition you write, then the database chooses how to scan and connect the tables, and finally it applies the updates one row at a time. Different systems may show different syntax, but the mechanics remain steady across them. Thinking about it in terms of how the database pairs rows and moves values makes it easier to write updates that keep related tables consistent.

{kind=link}