

Generating reports on demand can slow an application down when the process involves heavy database queries or complex formatting work. Moving this process into the background lets the main application stay responsive while still producing the report in full. The client can continue other actions without delay, and the system can handle more incoming requests without bottlenecks. In a Spring Boot environment, this can be done by running the report creation asynchronously, keeping track of its progress, and then notifying the requester once the work is complete. The process involves sending a report request, handling the processing away from the main thread, and sending an update when the report is ready.
How Async Report Generation Works
Handling reports without blocking the main thread keeps the application responsive. Instead of building the report during the same request that asks for it, the process is broken into separate steps. The request is accepted, the heavy work is moved to the background, and the progress is tracked so the client can see when it’s ready. This keeps the experience smooth for the user and allows the system to handle more load without slowing down.
Requesting the Report
The starting point is an endpoint that accepts a request from the client. Rather than returning the report itself, it responds with an identifier that the client can later use to check the status. This keeps the initial HTTP call quick while the real work is done elsewhere.

The registerReportRequest method stores the request details and generates a unique ID, often a UUID, to avoid conflicts between multiple reports. Along with the ID and status, it’s useful to keep details about who made the request and the type of report needed.

Capturing this extra data early makes it easier to troubleshoot later and helps maintain clarity if the processing logic changes over time.
Processing in the Background
After the request is recorded, the work should be done outside the main request thread so the application can respond immediately. Spring’s @Async annotation runs the method in a separate thread, allowing report generation to happen without holding up the response.
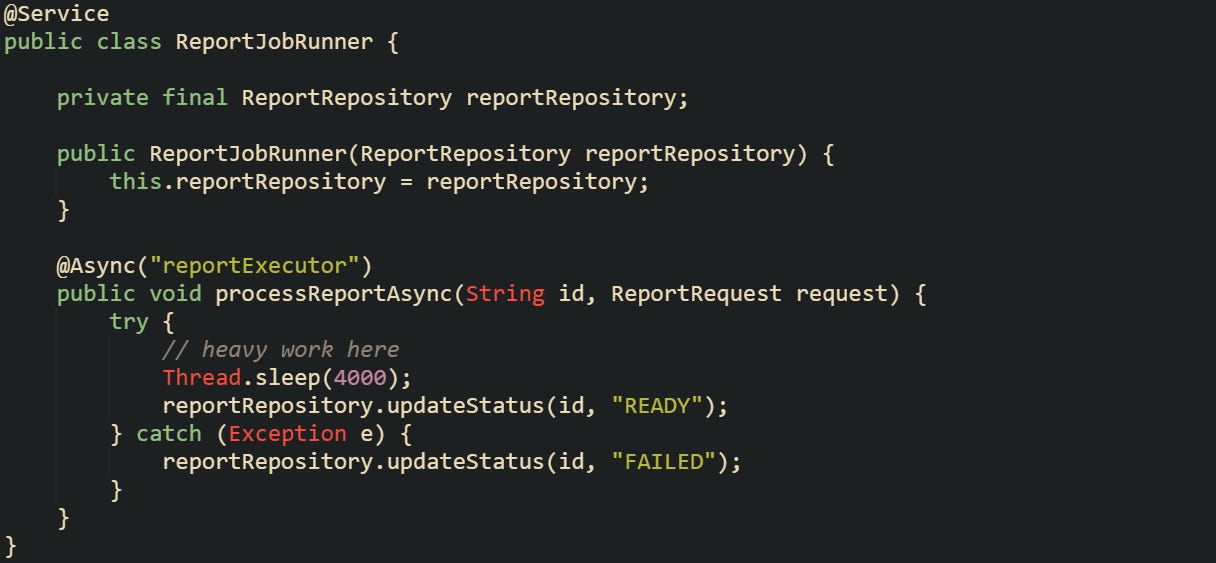
For heavier workloads, a dedicated thread pool can prevent these jobs from delaying other async operations.

With this in place, the processing method can be targeted to run on this specific pool.

This separation helps maintain consistent performance across different parts of the application.
Tracking Status
Clients need a reliable way to check progress without making assumptions. A status endpoint provides a simple way to return the current state of the report.

Statuses like PENDING, READY, and FAILED are common, but more detailed stages can be helpful for complex workflows.
In MySQL or MariaDB, a minimal table can keep the status and relevant timestamps:

This lets you track how long reports take, find failed reports quickly, and keep an accurate record of progress.
Notifying When the Report is Ready
Polling a status endpoint works fine for short jobs, but it can waste resources for reports that take longer to complete. A direct notification approach avoids repeated requests and gives the client immediate awareness of completion. This is where push-based communication like WebSockets or Server-Sent Events can make a real difference. The server can keep a connection open and send the update as soon as the report finishes.
Why Notifications Matter
When a report takes minutes instead of seconds, users often switch to other tasks while waiting. If they have to manually check back, it’s easy for them to miss when it’s ready. A notification removes that guesswork by sending the result or status update without requiring another request. For example, an email notification might be suitable for offline processes, while a persistent connection with the browser works better for interactive dashboards. Choosing the right method depends on how the application is used and how quickly users need the results.
Even a basic push model improves efficiency because the server tells the client exactly when the job is done.
Example with Server-Sent Events
Server-Sent Events (SSE) is a lightweight option for pushing messages from the server to the client over HTTP. Unlike WebSockets, SSE is one-way from server to client, which makes it ideal for notifications like report readiness.
Here’s a basic subscription endpoint:

The repository holds the emitter so it can be accessed later when the report finishes.
When the background job completes, the service can send the message:

The client listens for the event in JavaScript:

This keeps the connection alive without constant polling and closes it as soon as the notification is delivered.
Thread Pool Considerations
Long-running jobs can compete with each other if they all run on the same thread pool. Separating different types of background work helps prevent delays in unrelated features. Defining a pool dedicated to report generation allows you to control its capacity without affecting other asynchronous operations.

If you want notification handling to run independently from the report creation itself, you can use this pool for sending events:
Heavy report processing can sometimes slow down the moment a user is told their report is ready. Running the notification logic on its own dedicated pool keeps that update moving quickly, even when other background work is running at full capacity.
Conclusion
Asynchronous processing paired with a clear notification path keeps report generation from slowing the rest of the system. The mechanics come down to three moving parts working together: an entry point that records the request, a background process that handles the heavy work away from the main thread, and a way to push the result to the client when it’s ready. Each piece relies on Spring Boot’s ability to manage separate threads, maintain progress data, and deliver messages without interrupting other operations. When these pieces are in place, reports can be produced efficiently without blocking the user or overloading the application.
If you’d like to see another way to handle on-demand report generation, I’ve made a companion guide that covers a queue-based model with RabbitMQ or Kafka. It builds on the concepts here and shows how to offload jobs to dedicated workers for improved scalability and reliability. You can read it here:

