

Modern applications deal with data that doesn’t always line up cleanly with fixed columns. JSON helps with that by giving you a way to store flexible structures inside a single field. Both PostgreSQL and MySQL support it in a way that blends structured rows with extra data packed into a JSON column. But saving that data is just the starting point. Pulling values out, filtering based on what’s inside, and sorting results all work differently compared to regular columns, and the mechanics behind that shift the way queries behave.
How JSON Data Is Stored and Queried in PostgreSQL and MySQL
Storing JSON inside SQL columns gives you a way to hold extra structure without constantly changing your schema. They each validate, format, and store the data differently, and that choice affects how fast queries run, how indexing works, and how paths are resolved later when reading the data back. Getting familiar with how the column types behave can save time when structuring data for queries that need to filter or sort later.
Storing JSON as a Column Type
PostgreSQL gives you two options when creating a column meant for JSON. You can declare it as json, which stores the text exactly as it comes in, or jsonb, which parses the structure and saves it in a binary format. The jsonb type is more widely used because it lets the database work with the content more efficiently. It parses the input, strips whitespace, and sorts the object keys so it can compare or index the data faster. That does mean the stored format won’t always match what was originally inserted, but the structure and values stay the same.

MySQL uses a single JSON type, introduced in version 5.7. That column type stores the parsed structure as binary as well, so it doesn’t keep the raw string. It also checks that what you insert is valid JSON and rejects anything that doesn’t fit the format. In MySQL, there’s no option to pick between a raw or binary version like in PostgreSQL, but the stored format still supports working with arrays, objects, and nested values.

Both engines treat these columns differently from a regular text column. If you try to insert malformed JSON, the statement fails. Strings need double quotes, arrays need brackets, and object keys need to be quoted properly. The database checks and parses everything before it commits the row, so the stored value is valid JSON from the start.
How the Database Parses and Stores JSON
When PostgreSQL sees an insert into a jsonb column, it doesn’t just check the format. It builds an internal binary tree that represents the structure. It reorders object keys and flattens out any extra spacing. That helps with comparisons later, especially when it comes to checking equality or searching for specific shapes inside the data. Arrays keep their original order, but object keys don’t. This makes equality comparisons more predictable at the storage level and avoids false mismatches when comparing two logically identical objects written with different key orders.
Here’s an example of how that works:

If you inserted another row with the same keys in a different order, PostgreSQL would store them the same way under jsonb:

Both rows would be treated as equal when comparing their entry values because the structure gets normalized as part of the binary format. If the column had been declared with the json type instead of jsonb, then the whitespace and key order would be preserved, but comparisons and indexing wouldn’t be as fast or reliable.
In MySQL, the storage format also turns the JSON into a binary tree. Each value has a type marker and a length prefix, so the engine knows where each object starts and ends without needing to scan the text every time. Strings, numbers, arrays, and booleans are all stored differently inside that tree, and nested values are tracked by offsets from the beginning of the stored blob. When a query asks for a path like $.event.ip, the engine follows that path through those offsets without starting from the top.
Here’s an insert that stores a nested structure in MySQL:
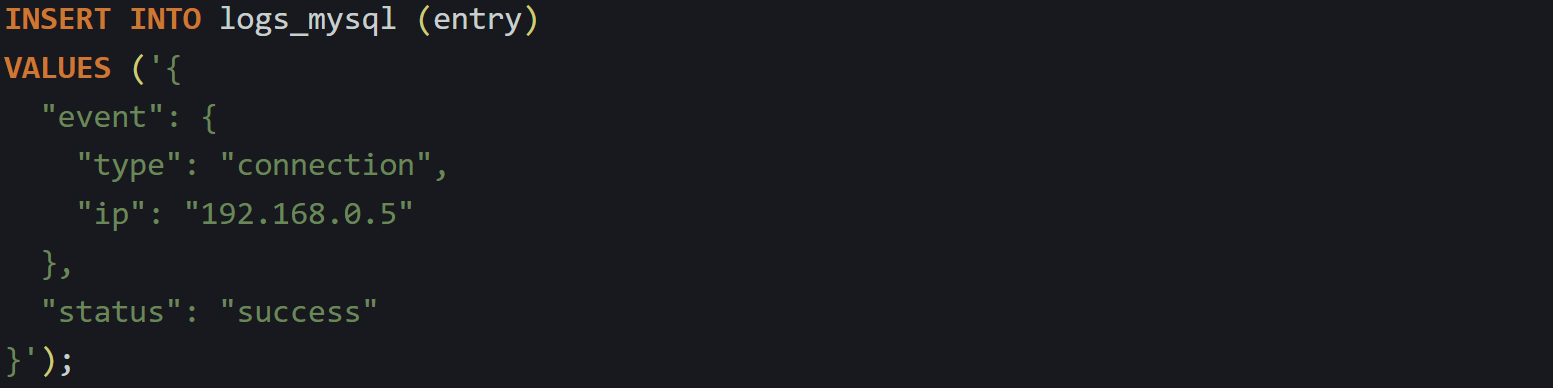
That data is stored as a nested binary object inside the column. The database keeps track of each object field and its offset, so when a later query pulls out event.ip, it can go directly to it instead of decoding the whole structure.
While the behavior on the surface looks similar between the two systems, the way they organize the data in storage shapes how filters, lookups, and sort operations work. PostgreSQL gives you more control by letting you pick between json and jsonb depending on the use case. MySQL focuses on a single storage model with a binary layout and typed values. Both engines fully validate the structure during inserts and store it in a way that supports working with structured values inside a single column.
Extracting, Filtering, and Sorting JSON Fields
Reading JSON from a database isn’t the same as working with flat columns. Values live inside nested structures, and to use them in filters or sort operations, you have to reach into those layers. PostgreSQL and MySQL both give you tools to do it, but the way they handle the process is a little different. The syntax and the return types affect how you write queries, how comparisons behave, and what kind of result you get back.
Getting Values Out of JSON Columns
Pulling a value from a JSON column takes more than just naming the field. In PostgreSQL, you use -> when you want a raw JSON object and ->> when you want plain text. That choice matters because text and structured values behave differently in comparisons, joins, and sorting.

The first pulls the entire object under the details key, while the second grabs the string inside status. That difference shapes how the result is treated in whatever comes next.
In MySQL 8.0 and later you can also use the ->> operator, which follows a JSON path and returns the unquoted scalar value. The plain -> operator (or JSON_EXTRACT()) still returns a JSON document, so use ->> when you need text that’s ready for comparisons or sorting.

PostgreSQL handles the difference between raw and text output directly through its operators.
Filtering by Nested JSON Fields
When filtering by values buried in JSON, you need to point to the exact path and compare it to something expected. PostgreSQL makes this easier by allowing the ->> operator in a WHERE clause just like a normal column comparison.

This query returns only the rows where the status field inside the JSON is equal to 'error'. Because the operator returns text, the comparison works as it would with a flat column.
MySQL does the same task with a path expression, but it also requires the value to be unwrapped if it’s stored as a quoted string.

The path walks through the JSON object and stops at the field named status.
You can also search deeper into a nested object. Let’s say you’re working with client metadata and want to find a specific browser. PostgreSQL can reach in like this:

And the MySQL version looks like this:

If the path points to something that isn’t there, both databases will skip the row instead of throwing an error. That’s helpful when not all records follow the same shape or include every field.
Sorting by JSON Values
Sorting works much like filtering, but the return type starts to matter more. PostgreSQL can sort directly on ->> because that pulls a string.

As long as the timestamp is in a sortable format like ISO 8601, the order will line up correctly. You can do the same with numbers or other sortable fields stored as text.
MySQL also supports sorting by values pulled from JSON, but you need to unwrap them if they’re quoted.

If the value isn’t wrapped in quotes and stored as a number or raw string, you can skip the unquote step.
When working with numeric fields stored as strings, PostgreSQL allows you to cast the value so it’s treated as a number during the sort.
This makes the sort follow number rules instead of string rules, which avoids problems like '10' being treated as lower than '2'.
MySQL doesn’t need a cast if the field is stored as a numeric JSON value, but if it’s wrapped in quotes, the same issue comes up. Sorting treats it as a string unless it’s converted.
Indexing JSON Data for Speed
JSON fields work well for flexible structure, but they aren’t fast to scan by default. PostgreSQL lets you create expression indexes on a path from a jsonb column. That gives the database a shortcut when filtering or sorting by the value at that path.

With that in place, queries that filter by status can skip scanning the entire table and jump right to matching rows. The database stores the extracted value during insert and update, so it doesn’t have to do the work again during reads. PostgreSQL also supports GIN indexes that let you index many paths at once, but that comes with extra storage and slower writes.
Before MySQL 8.0.13 you had to expose a generated column and index that column, but current versions support functional indexes. You can now index a JSON expression directly like this:

The optimizer can use this index in the same way PostgreSQL uses an expression index, so filtering and sorting on that path avoid full-table scans.
For older versions of MySQL (before 8.0.13), you had to define a generated column based on a JSON path and then index that column:

The generated column updates automatically when new data is added or changed, so the values stay current without manual updates.
Either method turns a slow operation into something much faster, especially as the table grows. Without indexing, each read has to scan the full JSON field and extract the path one row at a time. With the index in place, the query can go straight to what it needs.
Conclusion
Working with JSON inside SQL columns changes how the database handles each part of a query. Instead of reading fixed fields, it has to reach through a structure and pull values out by path. PostgreSQL and MySQL both support that, but each one builds and walks those structures in its own way. The path operators, return types, and indexing methods all shape how filters and sorts behave. When the structure and query match up, the results come back quickly and reliably.

{kind=link}