Reading Binary Data in JavaScript with Typed Arrays and ArrayBuffer
How raw memory gets structure in JavaScript


{kind=link}
Binary data shows up all over modern applications. It could be a file read from disk, a message sent over a WebSocket, or raw bytes from a Bluetooth device. Handling it the right way depends on tools built into the language. JavaScript gives you direct access to read and write binary through ArrayBuffer and typed array views like Uint8Array, which let you treat a block of raw bytes like a real data structure without extra libraries.
Storing and Accessing Raw Bytes with ArrayBuffer
Everything starts with memory, and in JavaScript, ArrayBuffer is the block you use to hold raw bytes. It doesn’t carry any structure on its own. You decide how to read and write the contents by attaching typed views that shape those bytes into real values. The buffer gives you a fixed-size chunk, and once it’s set, the size doesn’t change. This creates a predictable way to store and work with binary without needing third-party tools.
How ArrayBuffer Works Internally
An ArrayBuffer gives you a fixed-length chunk of memory. You create one by telling it how many bytes you want. The browser allocates that space in the memory heap and gives you a buffer object to represent it.

This creates a 16-byte buffer. On its own, you can’t do much with it. You can think of it like a drawer full of empty compartments. Each one holds a byte, but there’s no label or structure until you give it one.
Internally, the buffer is just raw space. JavaScript doesn’t expose low-level memory operations, so the buffer is a safe way to store and share binary data. This kind of memory predictability matters when working with streams or low-level protocols.
If you inspect the buffer directly, there’s nothing much to see.

The byteLength tells you how big the buffer is, but there’s no way to view or edit the contents directly without attaching a typed view.
Using Typed Arrays to Interpret Data
Typed arrays let you treat the buffer as a collection of actual values. These views come in different flavors, like Uint8Array, Int16Array, or Float32Array, and they all know how many bytes to read per item. Each one wraps the buffer and gives you a way to access the memory with the right type in mind.
Here, uint8 treats the buffer as sixteen 8-bit unsigned integers. So every item in that array takes up exactly one byte of memory. You can fill in values, loop through them, or pass this view to another function.
What makes these views useful is that they all share the same memory. If you attach another view, it reads from the same space, just in a different way.

The Int16Array reads two bytes at a time. So int16[0] combines the first two bytes (10 and 20) into a single 16-bit integer. How those two bytes are combined depends on the system’s endianness, which leads into the next piece.
Byte Offsets and Endianness
You don’t always want to start reading from the beginning of the buffer. Some binary formats place values at specific positions. Typed arrays let you start a view partway through the buffer and limit how many items the view sees.

This gives you a slice of the buffer starting at byte 4 and going through byte 7. The view doesn’t copy the data. It just creates a new window into the same memory.
When working with raw formats, the order of bytes matters. Some systems store values with the most significant byte first (big-endian) and others with the least significant byte first (little-endian). Most typed arrays follow the machine’s native byte order, which works fine if you’re just working on one system. But when you need to read or write with a specific byte order, DataView gives you that control.

The third argument lets you pick the byte order. You can mix and match this way too. It’s common to use a typed array for the general layout and a DataView for fields that need fine-grained control.
Reading back the value is just as easy:

This gives you a stable way to handle binary formats that were created outside JavaScript. For example, a PNG file or a custom message sent from a backend system might require a certain byte order. DataView helps keep that consistent no matter which platform your JavaScript is running on.
If you’re processing something more structured, you might use a series of typed views to break up the buffer by field. That can give you a quick way to map each part of a message without converting anything.

Each field pulls data from a specific location. You’re just reading bytes where you expect them to be. And again, there’s no copy involved. It’s all backed by the same memory space.
Typed arrays and views like these make it possible to write and read raw binary without reformatting the data. That matters if you’re dealing with size limits, network formats, or just want to stay close to how the data is really stored.
Why Views Matter and How to Use Them with Streams
Raw binary often comes in chunks. A file download, a network message, or a stream of sensor readings doesn’t always arrive all at once. It comes in pieces, and you work with it as it arrives. Typed arrays give you a way to read the contents directly, with just the structure you need.
Working with Streams of Binary Data
Modern browser APIs, like fetch and WebSockets, support streams. Instead of loading everything upfront, you can read incoming data as it’s received. These chunks are often ArrayBuffer objects or something that can be turned into one. After you have that buffer, you wrap it in a typed view to make sense of the bytes.
Here’s a basic example using fetch to stream a binary file:
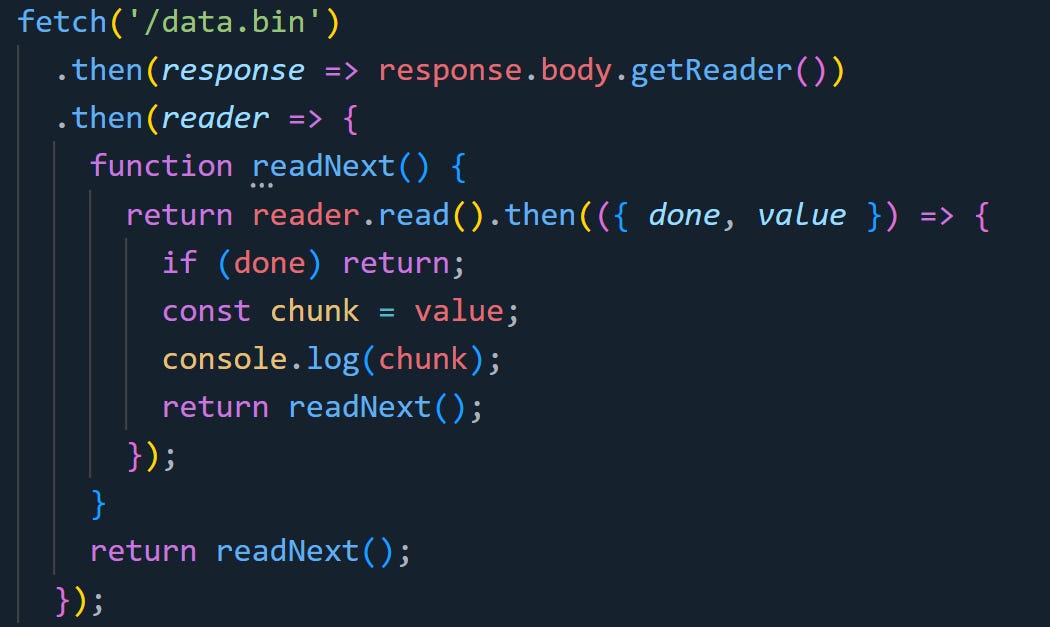
Each time a chunk comes in, it’s passed into a typed array. That gives you indexed access to the bytes right away. You don’t need to decode it or convert it. You just read it directly. This works well for large files or real-time data, where waiting for the entire payload would be wasteful. You can inspect headers, extract fields, or process payloads without keeping everything in memory at once.
Handling Headers and Structured Formats
Binary messages often follow a structure. You might have a header with metadata followed by a payload with the actual content. Typed views help you pick apart those fields without needing to shift data around.
Say a binary packet has this format: 1 byte for version, 1 byte for flags, 2 bytes for length, then a variable-length payload. You can map that with a DataView and a few byte offsets.
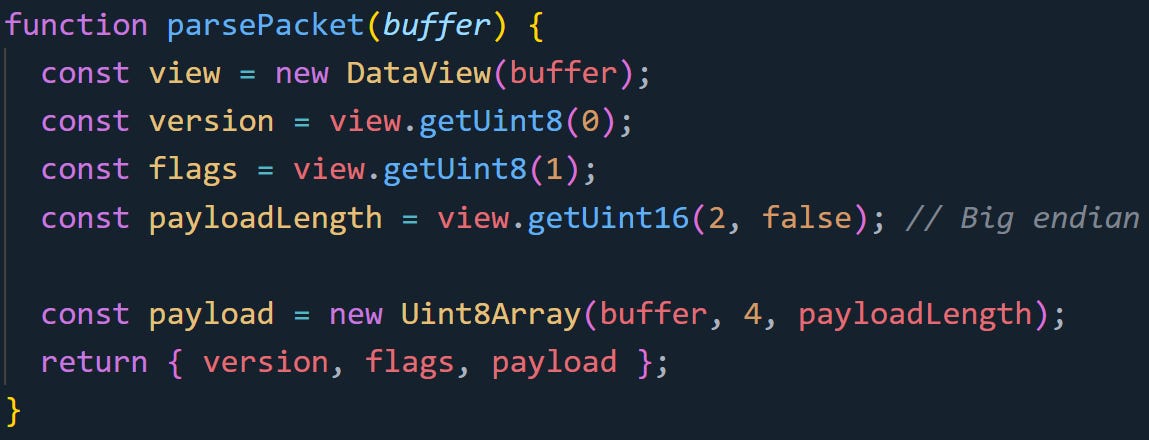
This reads the first four bytes using DataView for better control. Then it uses a typed array to read the actual content without copying anything. If the format changes, you just update the offsets. You don’t need a schema library or a decoding tool. Just grab the fields you need, then move on to the next message.
This is nice when working with streaming sources too. If you’re getting data in chunks, you can buffer the start of the message, wait until you have enough to read the header, and then check how long the rest needs to be.
Avoiding Copies and Extra Memory
If you slice a buffer into different views, all of them still point to the same memory.

Both header and payload use the same buffer. No new memory is created. That matters when you’re processing a stream or working with large inputs. If each slice made a copy, your memory usage would grow fast. This pattern shows up in file readers, media parsers, and protocols like WebRTC or Bluetooth. Instead of decoding to another format, you map the data to a typed view, grab the fields you need, and keep moving.
You can also reuse buffers. A single ArrayBuffer can be passed around with different views created on top of it, depending on what part of the data you’re working with.

This keeps your code clean and memory usage low. You’re working directly with the data that was received, without layering more abstraction on top or duplicating memory.
Typed views turn a stream of bytes into something you can work with directly, on your own terms, without having to reshape or convert it first.
Conclusion
Raw memory can be treated like something with shape and structure using typed arrays and ArrayBuffer. You're not building abstractions on top of the data. You're looking right at the bytes and mapping what they mean. The same chunk of memory can be viewed in different ways, read in pieces, or streamed into smaller buffers. Everything stays tight and direct. You decide where the data starts, how wide the fields are, and what each byte means. That control is what makes these tools so useful when working with binary.