

Go handles errors in its own way. Instead of throwing exceptions or relying on try-catch, it treats errors as values that you pass around and check yourself. That means you’re expected to stop and handle the problem right where it happens. You can tell what could go wrong just by looking at the return types, and the language doesn’t hide that from you.
How Go’s Error Handling Model Works
Go doesn’t rely on exceptions or a global panic chain to track problems. Instead, it takes a direct path where errors are handled right where they occur. This design leaves no confusion about what might fail, and it puts the decision in your hands about how to deal with it. There’s no hidden flow control, no automatic rewinding of call stacks, and no catch-all waiting somewhere above the call chain. The logic is up front and tied to the code that runs into trouble. That setup gives you a clearer story about what failed and when, and makes the checks feel like part of the normal logic instead of something you only add later.
The mechanics that make this possible aren’t complicated, but they are deliberate. What Go gives you is a small set of behaviors that stay consistent no matter how deep the call stack gets or how many packages are involved. And once you’re used to it, those patterns help you write code that’s easier to reason about line by line.
Errors Are Just Values
The error type in Go is built into the language and defined as an interface. It only has one method on it, which means anything that implements that method qualifies as an error.

That method is what gets called when you print an error or want its message. But what matters more is that errors are just regular values, like strings or integers. You can assign them, return them, compare them, or even pass them through channels. They’re not special cases that trigger control flow changes, and they don’t bubble up on their own. If a function wants to signal a problem, it just hands you an error value, and it’s your job to decide what happens next.
Here’s a short example of how that looks in a real function:
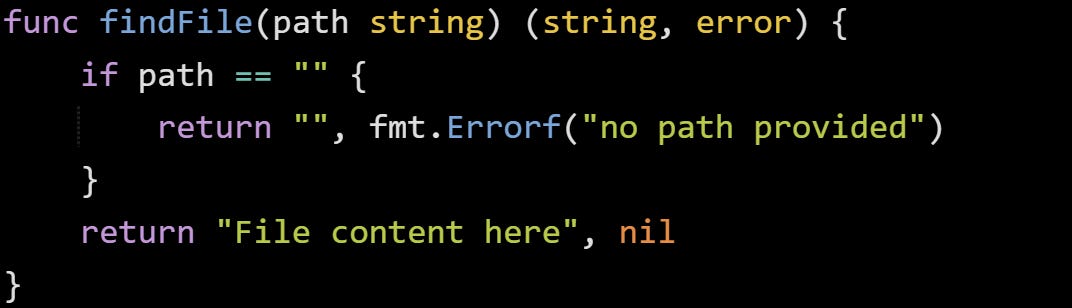
And the way you’d call it:
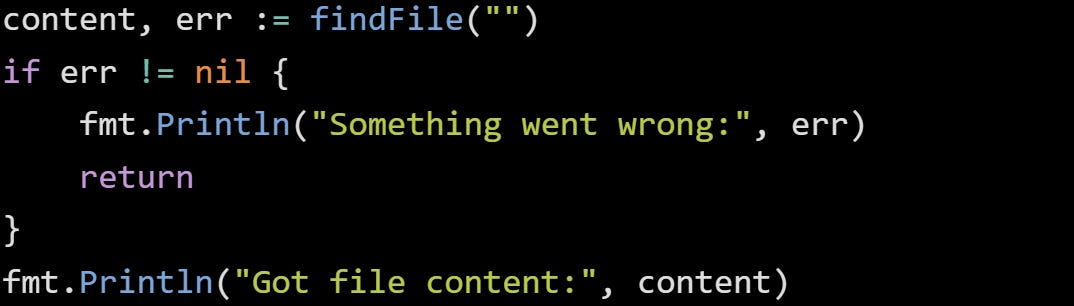
You check the value like you would any other. It’s just part of the control flow, no tricks involved. If you ignore the error, Go lets you, but the compiler will warn you if you assign it and don’t use it. That pressure to check your return values is one of the things that keeps error handling present and not forgotten in real-world code.
Why Go Chose This Model
One of the early design goals for Go was to keep execution paths easy to follow without jumping around. Exception systems often work by pushing control flow elsewhere when something bad happens. That means you might call a function that never returns, even though its signature doesn’t make that obvious. Go avoids that entirely. If something can fail, the function says so, and it does it with a second return value.
This plays especially well with concurrency. Go encourages splitting work across goroutines, but those goroutines don’t share control stacks. If a panic happens inside one, it won’t automatically be caught in another. That makes exceptions less practical. But returning error values works everywhere, and you can collect them or forward them however you like. There’s also the question of traceability. In exception-heavy systems, you often need stack traces to make sense of what happened. That can be useful but also noisy. Go’s model encourages building clearer paths upfront. When something fails, the surrounding code usually already explains what was attempted and what kind of response to expect.
Here’s another small example that returns early when something goes wrong, which is common in Go:
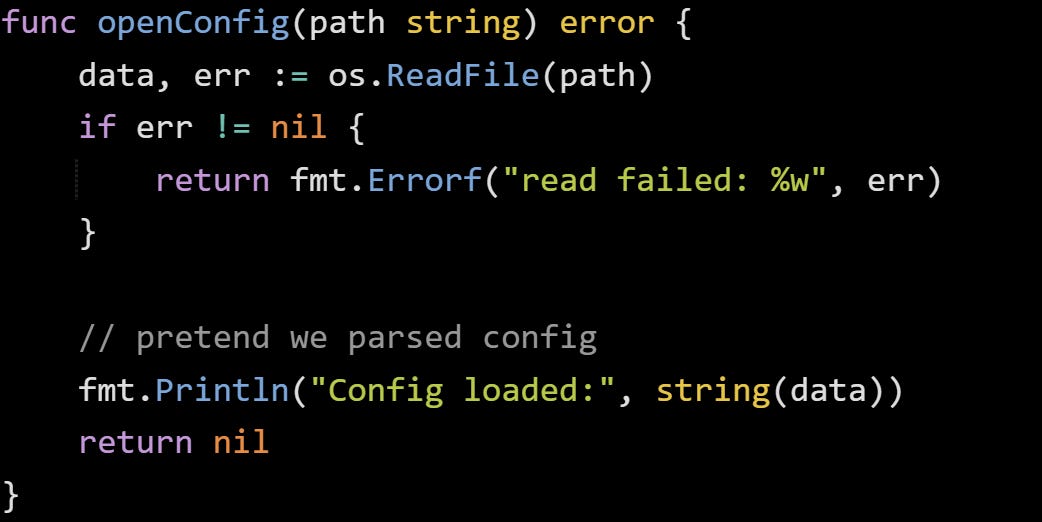
This function reads a file, returns an error if it fails, and stops right there. No further work happens after the error check, so there’s no chance of acting on bad data or assuming the read succeeded.
Returning Multiple Values
The whole pattern depends on Go’s ability to return more than one value from a function. Without that, error handling like this would be much harder to manage. This is one of the features that sets Go apart from many older compiled languages.
You’ll often see functions that return a result and an error side by side. The error always comes last, which makes it easy to scan and understand quickly. Here’s a basic example that fetches a number from a map:
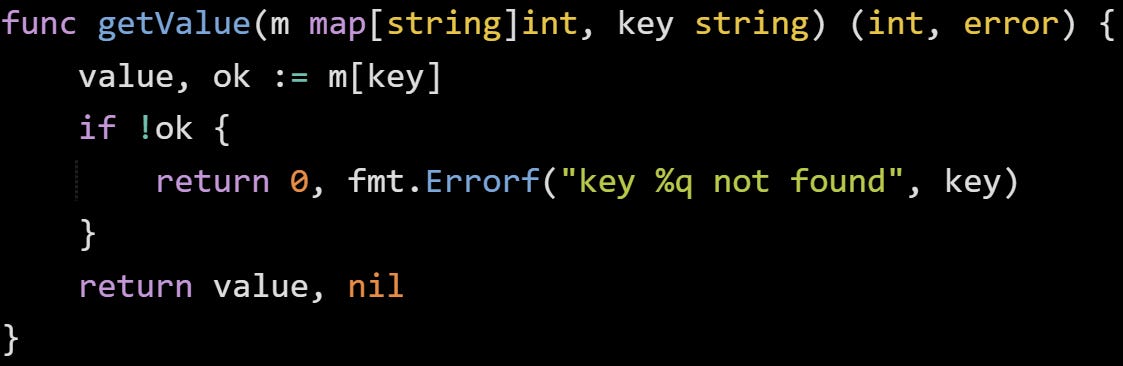
When you call this function, you check the second return value before trusting the first:
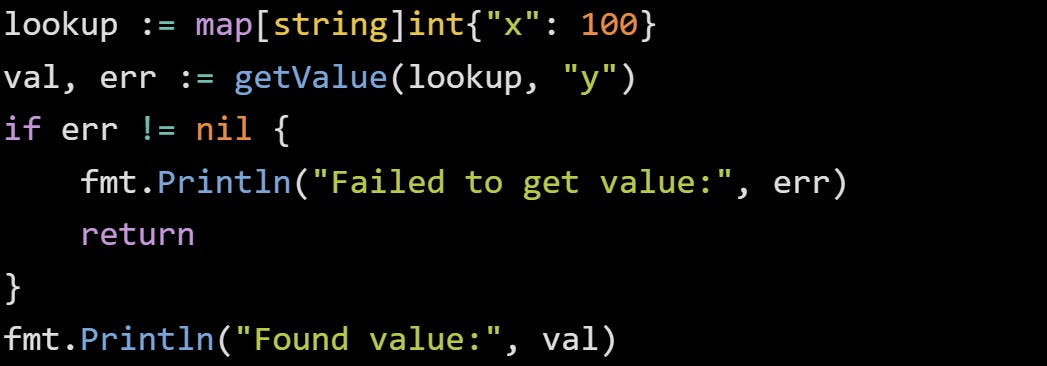
This also makes chaining errors across functions easier to follow. If you pass the error along from one function to another, it stays attached to the function where it started. You don’t have to decorate it with metadata or catch it with a special handler. You just return it, and if needed, wrap it with more context.
What this pattern encourages is a step-by-step structure, where you return early and pass the problem back. You’re not building recovery code far from where things failed. That habit, once it sticks, can make debugging a lot less painful. It also means your logs tend to have fewer surprises, because they reflect the same checks your code is doing.
Writing and Wrapping Your Own Errors
Basic error values get the job done, but they don’t always give you enough to work with when something breaks in a deeper part of your project. A plain error message like “connection failed” or “index out of range” might be fine for quick checks, but once you’re dealing with real application logic, you usually need more. That’s where custom error types come in. They let you hold onto extra context, group similar error cases together, and make decisions based on the type instead of just matching text. Wrapping those errors adds another layer by carrying history forward without throwing away the original cause.
Custom Error Types
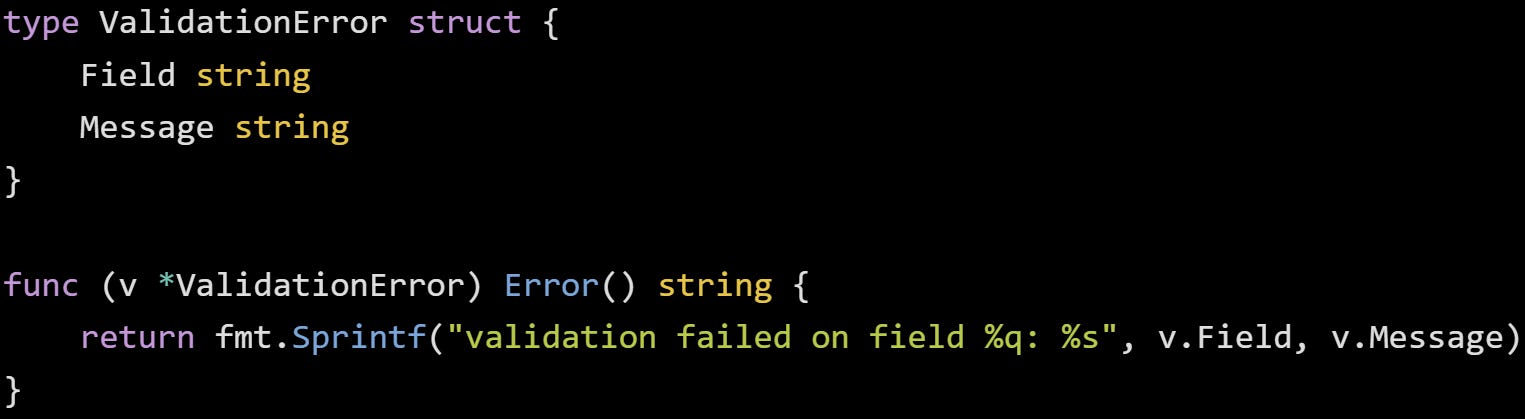
Any type with an Error() string method qualifies as an error. That means you can attach fields to your error and return more than just a sentence. It’s not about making things fancy, it’s about giving your code a way to carry information that’s actually useful when you’re trying to figure out what went wrong.
Here’s a small custom type for validation errors:
You could return this from a function that checks user input or config values:
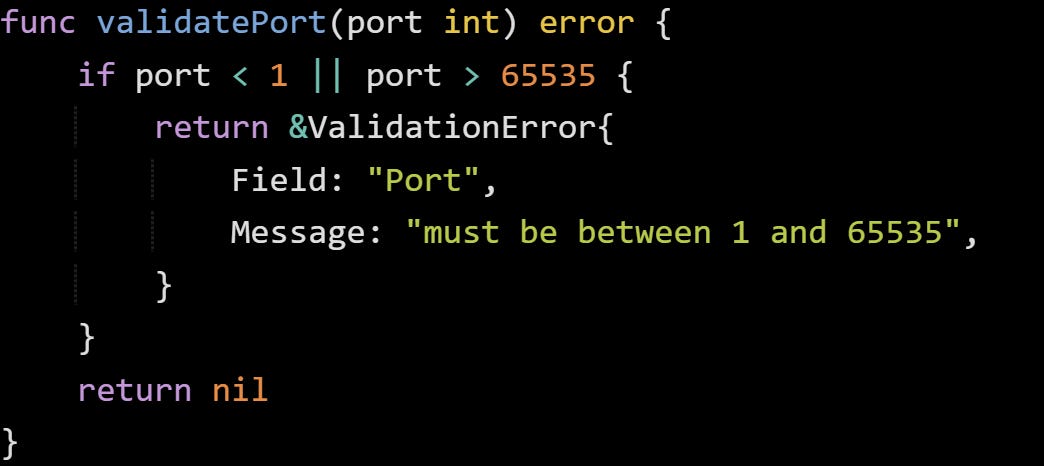
This gives you more than a one-liner. You can match it by type and pull out the field name or message without parsing strings. It also gives your tests something to check against besides string contents, which cuts down on fragile checks that break when you tweak wording.
Here’s what that can look like in a caller:

Instead of doing a bunch of string matching or building a custom error map, you just use Go’s type system. The error is still just a value, but now it carries structure with it. This also works well when you want to group related errors. You might have a NetworkError type with fields for the host and port, or a RetryableError that lets you retry based on type instead of message.
Using Errors With Context
Go 1.13 introduced error wrapping with %w, and that changed how people build and pass errors around. Before that, the best you could do was return a string with some context, but you’d lose the original error. Now you can wrap an error and still check for what started it.
Here’s a basic wrapped error:
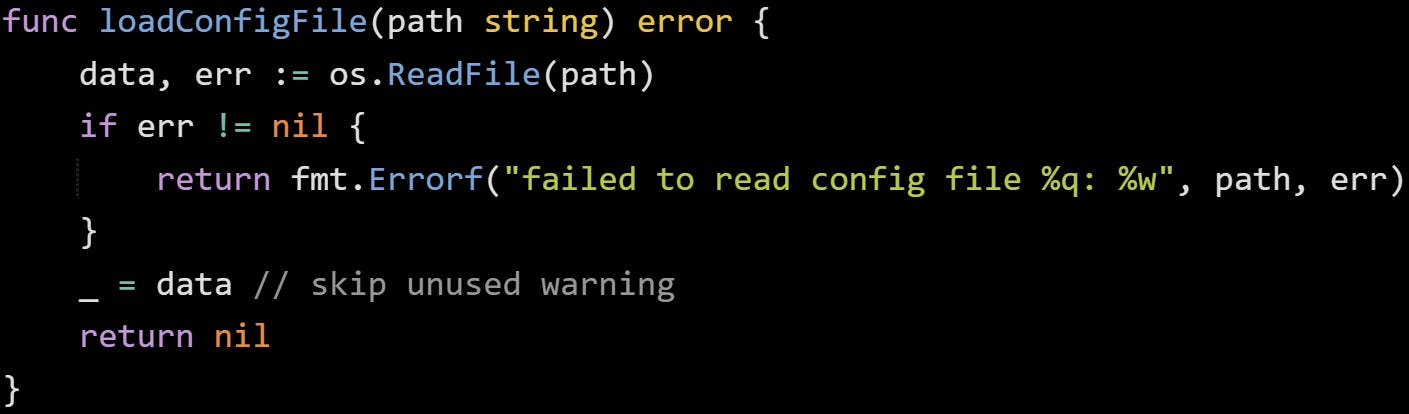
The fmt.Errorf call wraps the original os.PathError so you don’t lose what happened. You get to add your own message while still keeping the base error alive.
Now if you want to see if a file was missing, you can ask directly:

You don’t have to match on “no such file or directory” or peel apart strings. That’s the whole point of wrapping , you still have the full chain available to inspect.
You can also extract a specific error type with errors.As. That lets you go deeper than just checking if two errors match.

That’s useful when you want to handle a base case in one place but still log or recover from the more detailed part later. You’re not forced to bubble up special types or build a whole exception chain just to keep information alive. This pattern is common when reading files, making network requests, or chaining validation across layers. You wrap once and pass the full context up, and if something up top cares, it can pull the details out.
Helper Patterns
When you’ve got custom types and wrapping working, you’ll probably want some helper functions to keep the patterns readable. These aren’t required, but they make it easier to tag problems consistently without repeating the same wrap logic over and over.
Say you’ve got a database operation that fails in a few places. You could write a helper that standardizes the message and wraps the error cleanly:

Then anywhere that does a query can wrap like this:

This way, all errors related to queries get tagged the same way. You’re not doing anything clever, just keeping the wrapping consistent.
You can extend this idea to other layers too. One helper per boundary is often enough to keep logs and traces from turning into a guessing game. It’s also a good place to switch to structured error types if your system needs them later. Instead of changing a hundred scattered error strings, you just update the helper.
Another small pattern that shows up in real code is to combine wrapping with sentinels. Say you’ve got a known error that means something specific in your system:

You can use this in combination with wrapping like this:
Now callers can ask about the high-level cause without needing to care how it was wrapped:

These patterns keep things readable while giving you better tools to track what happened. You don’t need a full logging system baked into your error handling. Just having consistent types and wrapping gives you a big step up from plain strings. When done this way, your errors stop being noise and start being usable information.
Conclusion
Go’s error model works by treating problems as plain values that get passed and checked like anything else. There’s no hidden flow or stack trickery behind the scenes. You return an error, the caller handles it, and that’s it. With built-in support for wrapping and type checks, you can carry detailed context without giving up control. What makes this work is how consistent and visible it all is. The mechanics don’t change depending on where you are in the call chain, and once you’re used to it, the pattern becomes second nature.
good read!