

When working with data, sooner or later you’ll run into empty spots that show up as NULL. They can throw off calculations, make reports harder to read, and create awkward gaps in results that people rely on. The COALESCE function was designed to handle this problem directly at the database level. It checks a list of values in order and returns the first one that’s not NULL. That makes it a practical way to fall back on alternate columns or placeholder defaults without having to write extra logic outside your query.
How COALESCE Works in Queries
When people first encounter COALESCE, it can look like a simple helper that swaps out NULL values. What’s happening in the background is more than just swapping, though. Databases treat NULL differently than normal values, so the engine needs a clear process to evaluate which argument to return. This is where COALESCE follows a strict order, checking one argument after another from left to right. That short-circuit logic means it doesn’t waste time checking more arguments after it finds one that’s valid. To see why this matters, let’s walk through how databases evaluate expressions inside the function and then how they decide which data type the result should have.
Expression Evaluation
Every SQL engine has rules for how expressions get evaluated, and COALESCE is no exception. When the query runs, the database pulls the row into memory and starts checking the arguments in the order you listed them. As soon as it finds a value that isn’t NULL, it returns that value and skips everything else.
Think about a student records table with optional phone numbers spread across different columns. The query below looks at multiple contact fields and picks the first non-NULL entry:

If a student has a primary phone, the database never checks the secondary or emergency columns for that row. That behavior not only makes queries faster but also makes sure you don’t get unexpected results if later fields hold values that should only serve as backups.
You can also use expressions inside COALESCE, not just plain columns. Suppose a table stores scores, but sometimes the recorded exam value is NULL. A calculation can be added directly as one of the arguments:

For the code above, if exam_score is missing, the database falls back to half the homework score. The engine evaluates from left to right, and if exam_score exists, it never runs the multiplication. That’s a detail worth noticing because it prevents wasted calculations across large result sets.
Compatibility of Types
Beyond picking the first non-NULL value, the database has to decide what type the result should be. This part can feel less obvious, but it’s important. SQL requires that the result of an expression has a single type, so if you pass arguments of different types, the engine applies type precedence rules or demands explicit conversion.
SQL Server resolves the return type using data type precedence. int outranks varchar, so SQL Server tries to convert the string to an integer, which can fail. Cast the numeric to text when you want a text result.
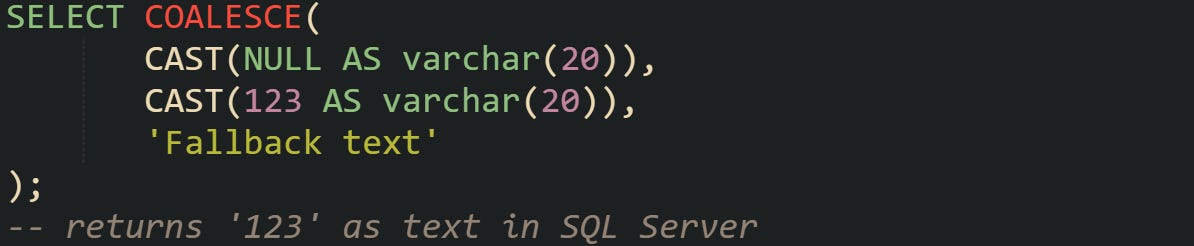
PostgreSQL, on the other hand, is stricter. If you try the same thing there, you’ll get an error because it doesn’t implicitly assume how to merge numbers and text. The fix is to cast the value so that the database knows the intended type:

Now the query succeeds, and the result is clearly text.
Type precedence can also affect calculations. A case where numeric precision matters shows why this behavior is worth keeping in mind. Suppose one column is INTEGER and another is NUMERIC:

Here, most databases will promote the result to NUMERIC, because it preserves precision. If you don’t realize this, you could end up with a result type that has more storage overhead than expected. That’s usually fine, but being clear about the type helps avoid surprises in downstream queries.
Something to think about is that literal values without quotes are treated differently than string literals. Passing 0 versus '0' changes how the function evaluates type compatibility. Writing out casts is a safe way to control this. It’s not about verbosity but about being clear to both the engine and anyone else reading the query later.
Practical Uses of COALESCE
Real strength of COALESCE comes through when it’s applied in everyday queries. Data rarely looks perfect, so handling missing values directly in SQL saves extra steps and produces results that are more reliable for both reports and applications. When the goal is to provide fallback text, merge columns that overlap, or keep calculations from breaking, this function keeps things consistent without adding layers of conditional logic elsewhere.
Reports with Placeholder Defaults
Reports often need to be presented in a way that’s clear to the end reader. Seeing a blank cell can be confusing, particularly when it’s unclear if the value was missing or if the query failed to pick it up. With COALESCE placed in the query itself, every row returns something presentable, even when the actual data is absent.

For this code, rows without a tracking number still return a meaningful string, which makes the report more understandable to someone reading it outside the database context. There are cases where a default numeric placeholder works better than text. A company tracking employee bonuses may want missing values displayed as zero rather than blanks:
Totals remain accurate when summed across departments, and the report avoids misleading gaps.
Combining Multiple Sources
Data migrations or schema changes often leave systems with overlapping columns. Rather than forcing applications to check which field holds the valid value, COALESCE can handle the transition directly inside the query.

If the new field has been filled in, it takes priority. If not, the legacy column provides the fallback.
Names often raise similar issues. A dataset could have separate values for preferred names and legal names. With COALESCE, you can give preference to the chosen name while falling back if it isn’t recorded:

The result is a presentation layer that remains consistent without requiring downstream systems to check multiple fields.
A different place where this function proves valuable is in financial systems that keep both provisional and finalized numbers. A provisional figure may be entered first, with the official value added later. Queries can be structured to always show the most accurate number available:

This makes reports stable while still honoring the most recent and precise data. If both amounts are absent, the result defaults to zero, which helps maintain consistency across reports without leaving unexplained blanks.
Handling Calculations
Arithmetic involving NULL values often leads to blanks in the output. That happens because any operation with NULL produces NULL. Wrapping those inputs with COALESCE provides default values that keep the math reliable.
A sales system may track discounts across several promotions. If one of them is missing, the total discount calculation should still work:
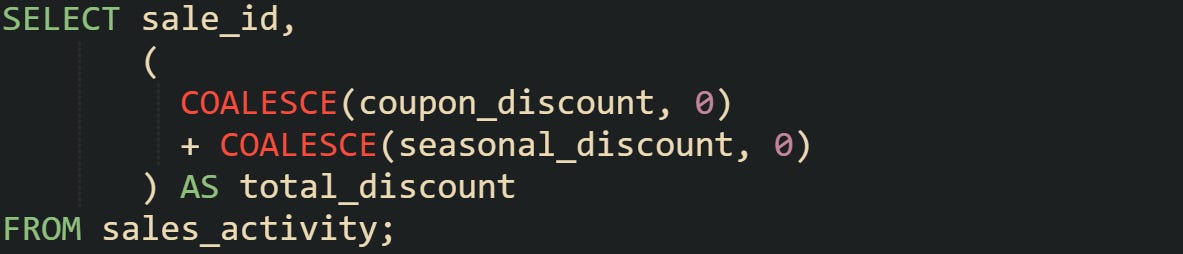
Columns are replaced with zero when missing, so the arithmetic remains intact.
Survey data provides another example. If some responses are absent, those blanks shouldn’t stop you from calculating an adjusted average:

This way, every row contributes to the average, though the choice of zero should match the expectations of whoever will interpret the results.
Integration with Joins
When queries involve LEFT JOIN, unmatched rows naturally create NULL values. Those blanks can cause confusion in reports or distort aggregates if left unchecked. COALESCE helps fill those gaps.
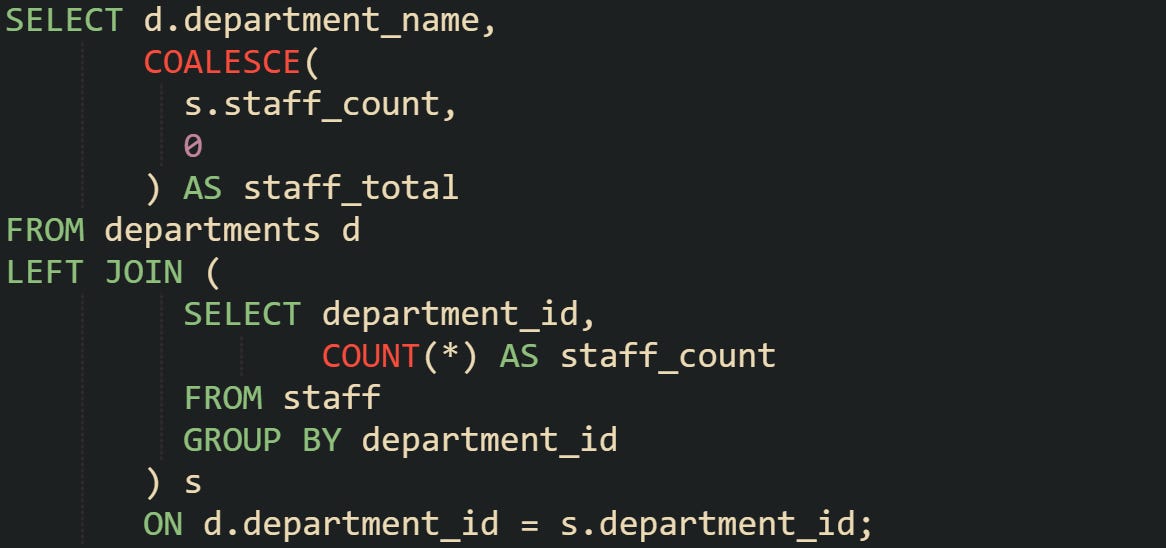
Departments with no staff entries will still return a count of zero, giving a complete view across the organization.
Finance data presents a similar challenge. A customer without transactions should still appear in an account report with a balance of zero, not a blank:
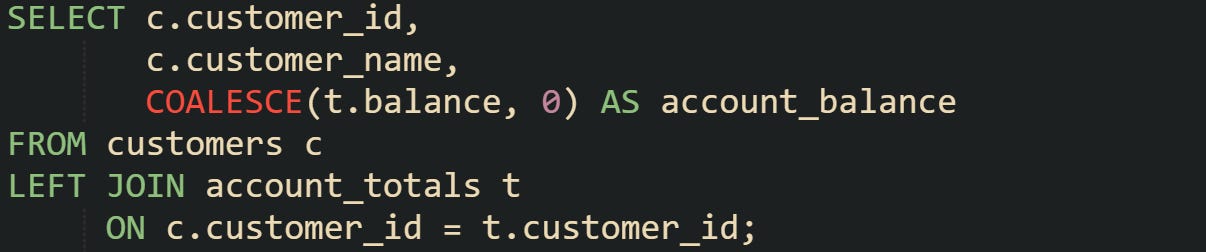
This makes the dataset easier to work with because it avoids missing rows or confusing gaps that would otherwise need interpretation later.
Alternative to ISNULL or NVL
Different database platforms have their own functions for handling missing values, such as ISNULL in SQL Server or NVL in Oracle. Both of those are limited to two arguments, which makes them less flexible when multiple fallbacks are required. COALESCE accepts many arguments, which makes it more useful in situations that need more than two possible values.
A simple SQL Server example shows the difference:

With COALESCE, more values can be included:

This makes it easier to build queries that remain valid when more fields are added later. Because COALESCE is part of the SQL standard, it also travels better across platforms. Oracle, PostgreSQL, SQL Server, and MySQL all support it, so queries that depend on it are more portable compared to ones tied to vendor-specific functions.
For anyone working in environments with multiple databases, relying on COALESCE reduces the need to rewrite queries when switching systems. It becomes a habit that saves time, because the same query logic continues to work across different platforms without modification.
Conclusion
COALESCE works by walking through its arguments one at a time, returning the first entry that isn’t NULL and skipping the rest. That short-circuit process is handled directly by the database engine, which makes it both reliable and efficient. It also has to settle on a single output type, which is why type precedence and explicit casting come into play. These mechanics explain how it manages to turn incomplete data into results you can trust, from filling blanks in reports to lining up fallback columns to keeping calculations intact.

{kind=link}