Where Java Anonymous Classes Live in Memory and How They Behave
Inside Java's anonymous class system


Anonymous classes in Java are a long-standing feature used to define small chunks of behavior without creating a separate named class. You usually see them when passing behavior as an object, such as implementing interfaces or extending classes on the fly. While they’ve been partially replaced in some cases by lambda expressions, they’re still part of the language and runtime today. What’s less commonly discussed is what actually happens to these anonymous classes when your code is compiled and run.
How Anonymous Classes Are Compiled and Loaded by the JVM
They’re those little snippets you squeeze into a method or constructor when you don’t want to write a full separate class. Java treats them as anonymous classes. They let you create an object that implements an interface or extends a class, all in one go. The code might look compact, but behind the scenes the compiler still turns that snippet into a real class with a real .class file and a real place in memory.
How Java Source Gets Transformed
Let’s say you’ve got a method that needs a one-off implementation of Comparator:
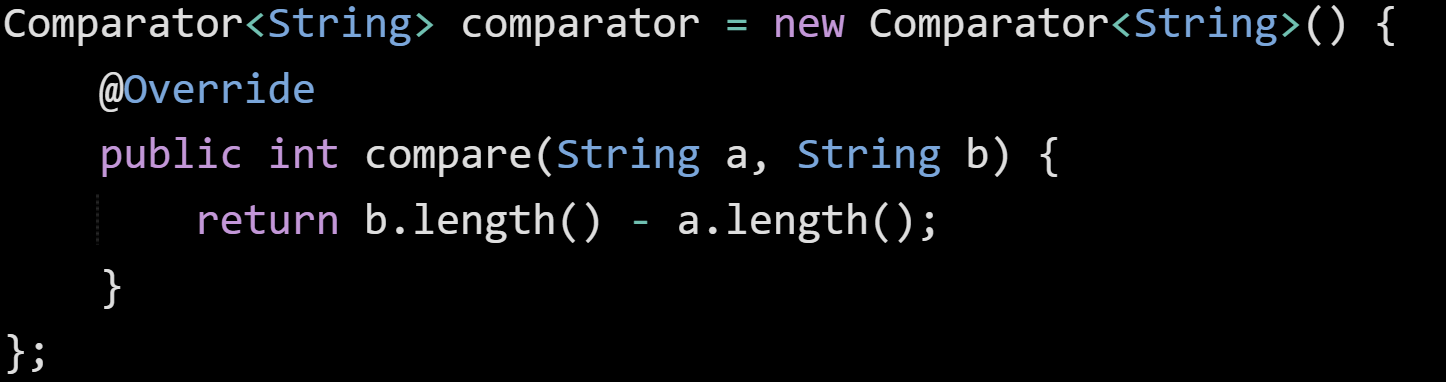
When the compiler sees this, it builds a new class. If this snippet lives in a class named SortHelper, then the compiler creates a file named SortHelper$1.class. The dollar sign and number show that it's the first anonymous class inside SortHelper. If you had a second one in the same class, it would be SortHelper$2.class, and so on.
This new class implements Comparator<String> and overrides the compare method. For example, if that compare method used a threshold defined in the method where it was written, that value would get passed into the anonymous class's constructor and stored as a hidden field.
So even if the code looks tiny, it still produces a class file with its own constant pool, method table, and internal name. It’s fully compiled like any other class you’d write by hand.
Memory Location and Lifecycle
The memory layout for anonymous classes doesn’t involve anything exotic. When the JVM loads one of these classes, it sticks the class metadata in the metaspace, which replaced the old permanent generation in Java 8 and later. The JVM stores the class metadata (methods, fields, constant pool) in metaspace and creates a java.lang.Class object on the regular heap that points to that metadata.
When you use the anonymous class to create an object, like calling new Comparator<>() { ... }, that object gets created on the heap like any other. So the actual behavior object lives in heap memory, while its structure and metadata live in metaspace.
Say you use a variable from outside the anonymous class:
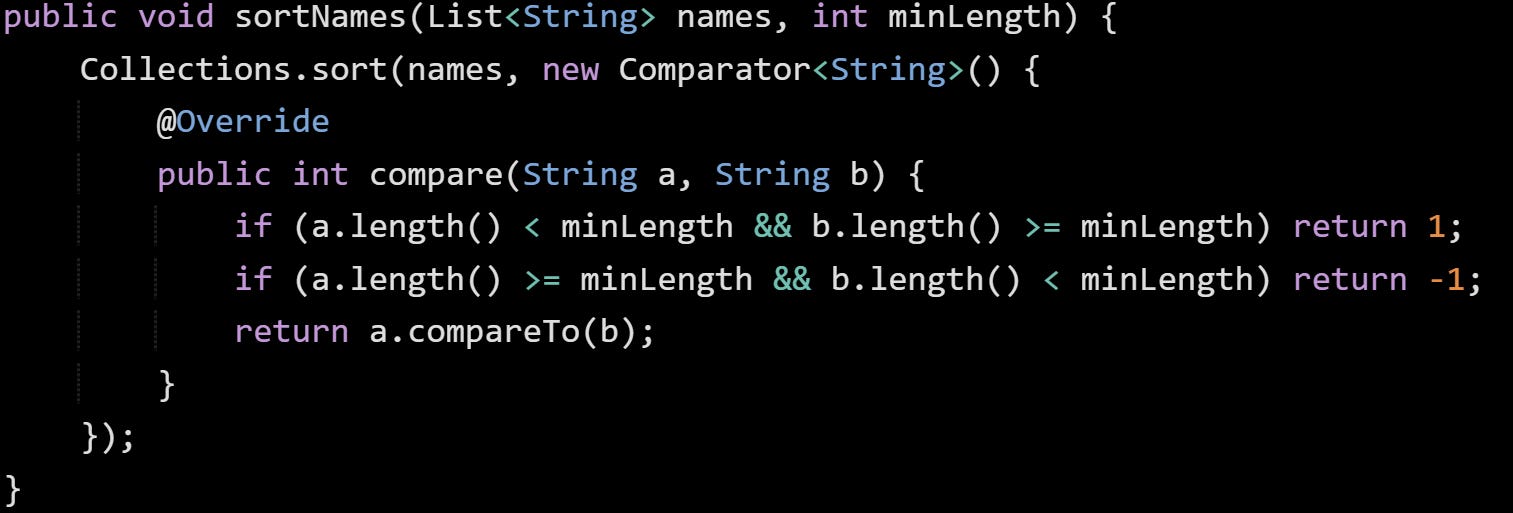
Here, minLength is pulled in from the enclosing method. That value gets baked into the anonymous class’s constructor and stored in a field that isn’t part of your source code. The compiler injects it during compilation. You can think of it like this: the object on the heap will carry around that value as part of its internal state, but the code that created the class structure only runs once and stays in metaspace. This is also why the JVM can garbage collect the object itself when it’s no longer used, but the class metadata will hang around in metaspace until the class loader that loaded it is eligible for collection. That’s usually when the application shuts down or the class loader is unloaded, depending on how your app is structured.
Class Loading and Identity
Each anonymous class is its own real class, even though you didn’t give it a name. That’s important. The compiler generates it with its own internal name, and the JVM tracks it like any other type. It’s got its own constant pool, its own set of method references, and its own class-level identity.
Here’s what that means in practice, if you write two anonymous classes that look the same, they’re still separate types. The JVM doesn’t merge them, and you can’t cast one to the other unless they share a parent interface or base class. Even then, the actual types remain different.
For example:

These two classes get compiled into MyApp$1.class and MyApp$2.class if you’re writing them inside MyApp. They don’t share a type identity, even if both just implement Runnable. If you inspect their class objects at runtime using r1.getClass() and r2.getClass(), you’ll see that they’re two separate classes.
If an anonymous class needs to call a method or access a field in the outer class, the compiler will add a reference to the outer class as another synthetic field. This is usually done automatically and only added if needed. So if the anonymous class never refers to anything outside itself, it won’t keep that extra reference around.
Here’s an example with a captured outer reference:
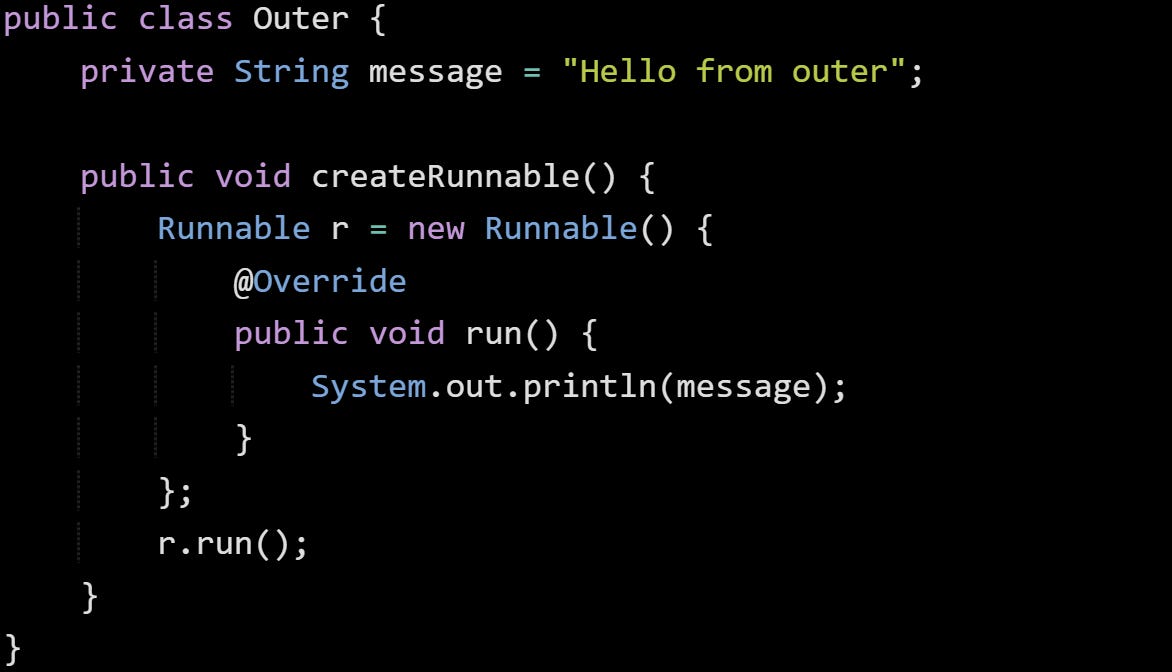
The compiled anonymous class will end up holding a reference to the outer Outer instance so it can access message. That reference is passed to the constructor when the anonymous class is instantiated. The JVM sees it as just another argument, and it gets stored as a hidden field, just like any captured variable. The class won’t be loaded until it’s actually used. The JVM doesn’t load anonymous class files during class loading of the outer class. It waits until your code executes the path that creates the anonymous class. That saves memory and startup time when anonymous classes are tied to optional code paths.
If you open up the compiled .class files with a decompiler or javap, you’ll see that anonymous classes look just like any other class file with bytecode and methods. They’re fully first-class types as far as the JVM is concerned.
What Makes Anonymous Classes Different from Lambdas
Anonymous classes and lambdas often show up in the same situations, like when you’re working with functional interfaces or writing callbacks. They let you define behavior on the spot, but that’s where the similarities stop. What happens at compile time and runtime is very different. These differences affect how code is loaded, how much memory it takes up, and how the JVM deals with it behind the scenes.
Class Generation vs Runtime Invocation
Anonymous classes always get turned into separate .class files. You can see them appear alongside your main class in the build output, each with a dollar sign and a number in the filename. That tells you they’re real, standalone types. The compiler builds each one with its own constant pool and bytecode, and that class stays alive for as long as the class loader that loaded it remains in memory.
Lambdas don’t leave behind extra files. Instead of generating a new class file, the compiler turns them into a invokedynamic call that points to a method handle. The JVM then uses LambdaMetafactory to produce an instance of the functional interface at runtime. It only does this when the code path reaches that lambda, so nothing is generated ahead of time.
Let’s walk through an example:
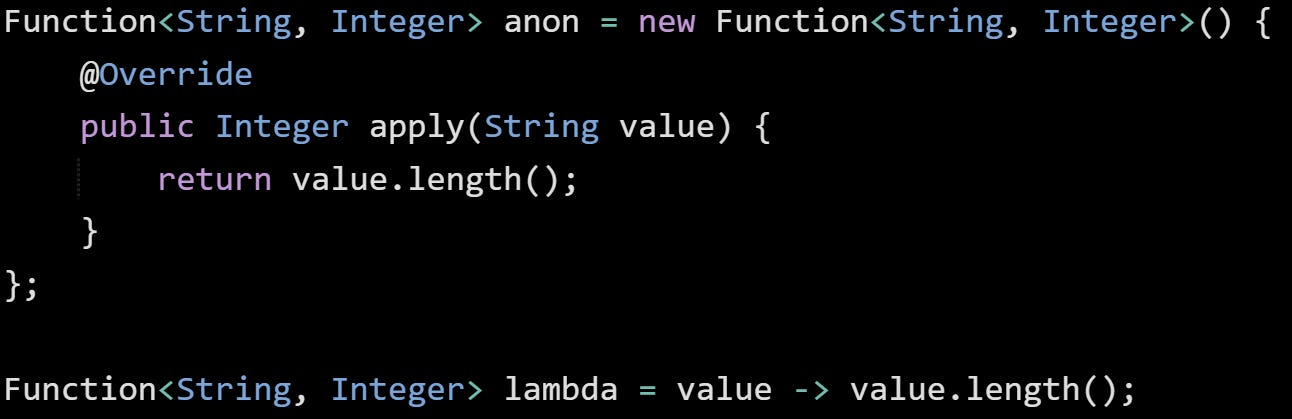
Both of these return a function that takes a string and returns its length. The anonymous class turns into a new class file like MyApp$1.class, and the object it returns has a distinct class type. The lambda compiles into a reference to a static or private method (depending on how it was written), and then the JVM builds a lightweight instance when it’s needed. There’s no extra class file lying around for the lambda.
You can also see this in action by checking the class of each at runtime:

The anonymous class prints something like class MyApp$1. The lambda prints something more dynamic, like class MyApp$$Lambda$3/0x0000000800c14440, which shows that it was generated on the fly. This distinction means lambdas take up less permanent space in your compiled code. When the same stateless lambda runs again at a single call site, the JVM hands back the same instance, but a lambda written in a different source spot produces its own synthetic class. Anonymous classes, on the other hand, will always produce separate types, even if they do the same thing.
Variable Capture Rules
Both lambdas and anonymous classes can access variables from the surrounding context, but the rules are a little different. The compiler treats lambdas more like pure code blocks and treats anonymous classes more like full-blown types with their own scopes.
Say you’ve got a method like this:
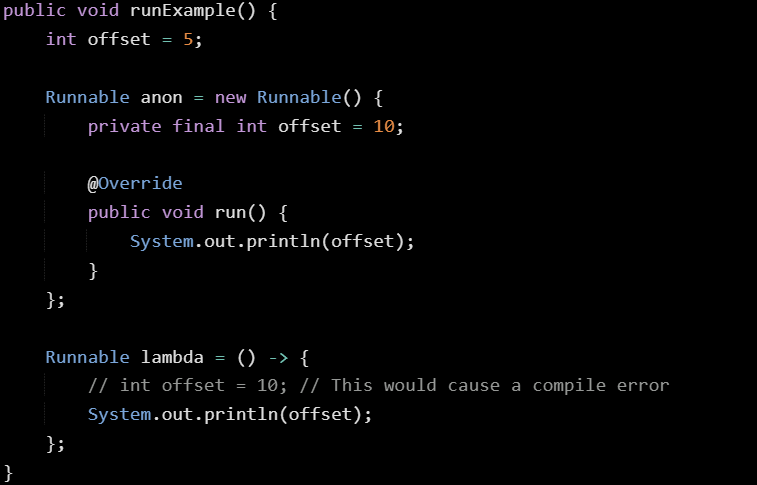
The anonymous class introduces a new variable called offset without any trouble. The lambda can’t do that. It’s using the surrounding variable directly and can’t declare another one with the same name. This happens because lambdas don’t introduce a new scope for local variables. The anonymous class does.
Captured variables must be effectively final in both cases. That means once the variable is assigned, it can’t be changed. The compiler enforces this to avoid weird side effects when behavior is passed around.
When a variable is captured, the compiler rewrites it into a synthetic field. For an anonymous class, it becomes part of the class definition, gets passed in during construction, and sticks around as part of the object’s state. For lambdas, the JVM can often store the captured value directly as part of the generated function object. If it’s stateless, the JVM may reuse the same instance.
Synthetic Methods and Bridges
Anonymous classes sometimes need help getting access to private members of the outer class or enclosing method. The compiler handles this by generating synthetic methods. These aren’t written in your source code but appear in the compiled .class files. They act as bridges to get around access control so that your anonymous class can call private stuff without a problem.
Here’s a simple example:
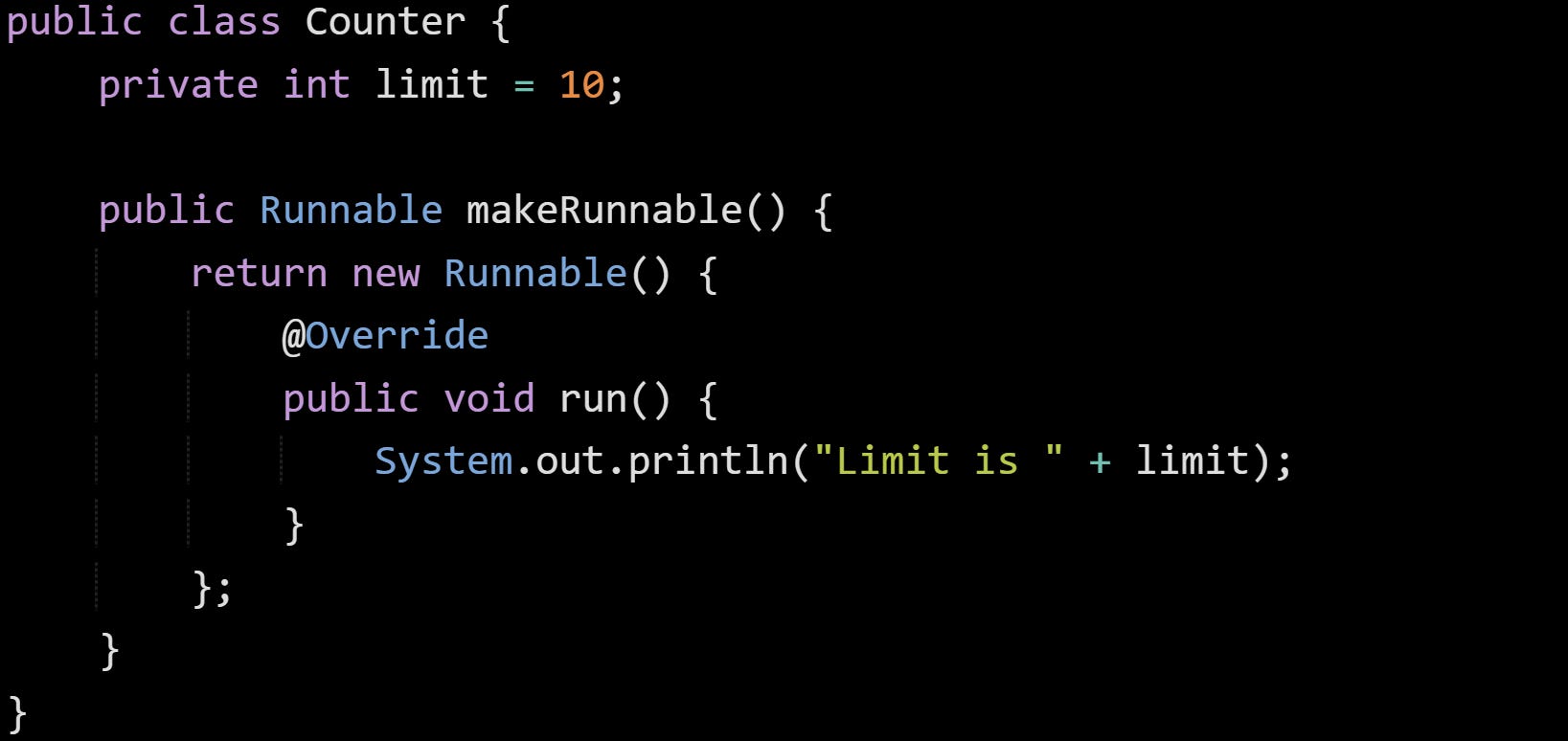
When compiled, the Java compiler sees that the anonymous class wants to access limit, which is private. It generates a method like access$000(Counter instance) that just returns the value of limit. This method is synthetic, marked as such in the bytecode, and used only internally. The anonymous class calls this method instead of trying to reach the field directly.
You can confirm this by using javap -p on the compiled class file:

You’ll find a static method that wasn’t in your source code but is now part of the final bytecode.
Lambdas don’t need this kind of bridge. The JVM handles access checks differently when generating them. Because lambdas are implemented through method handles and dynamic calls, the access control is handled at the bytecode level during the invokedynamic link phase. There’s no need to spin up a new helper method just to get to a private field. This makes lambdas a bit more lightweight when they deal with private members. They get their references and execute directly without extra glue code. That also means fewer synthetic methods cluttering your compiled output.
Conclusion
Anonymous classes and lambdas both let you pass behavior around, but they take very different paths after compilation. Anonymous classes become full types with real class files, their own identity, and extra methods when they reach into private parts of the outer class. Lambdas skip the class file, get built at runtime through method handles, and often reuse the same instance if they don’t hold state. The JVM tracks and handles each of these differently, shaped by how they’re created, stored, and called when your code runs. That difference explains why they behave the way they do.