

Writing SQL Queries That Run Faster
Real-world ways to cut lag using smarter filters, better indexes, and queries that match how the engine actually works.


Performance issues often come from the database, not the code you wrote on the surface. Query speed isn’t about shortcuts or clever tricks. It comes down to how the database processes your request and how your query shapes the path it follows. Faster results come from writing queries that work with the engine, not against it. That means using indexes the right way, avoiding costly patterns like wildcards, and writing joins that don’t pull in unnecessary data. Real queries show how small changes in structure can cut down on time and resource use.
Better Indexes That Work With the Query
Indexes help the database skip over data it doesn’t need. Without one, the engine reads every row in the table to check if it matches. That takes time, especially as the number of rows grows. With a good index in place, it can jump right to the rows you’re asking for and skip the rest. But having an index isn’t the same as using it. The way the query is written controls whether the database takes that shortcut or ignores it completely.
What Indexes Actually Do
A regular index on a column like last_name acts like a sorted map pointing to rows in the table. When you write a query that filters on that column, the database can use the map instead of scanning every row. That shortcut makes the lookup faster.
Here’s a basic example:
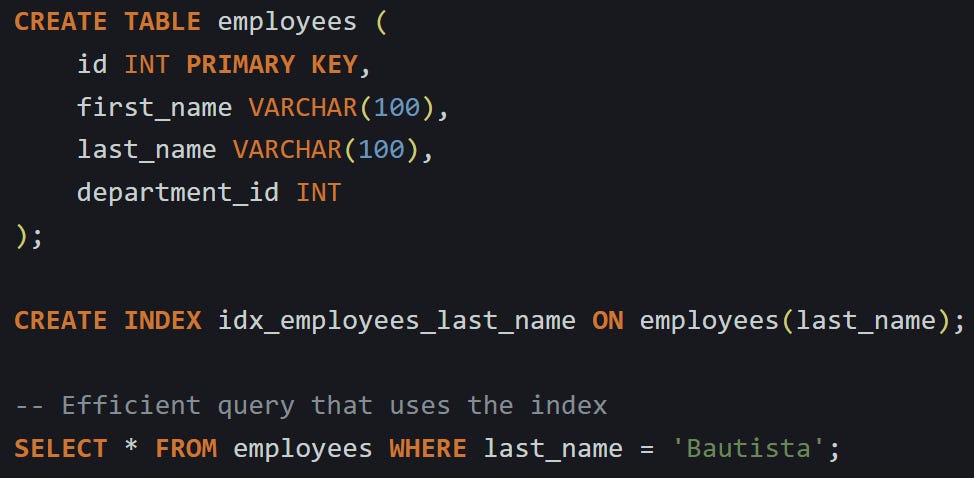
The filter matches the index exactly. That tells the planner it can scan just part of the table using the index and jump to the matching rows.
But that shortcut gets blocked if you change the shape of the filter:

Now the database has to apply the LOWER() function to every row before checking if the result matches. Most engines can't use the index anymore. Instead of skipping rows, it has to scan every one and transform the value before checking.
If you’re dealing with case-insensitive search, some engines support indexes that already store lowercase values or use special collations. For example, in PostgreSQL:

That index stores the transformed value ahead of time, so the query doesn’t need to apply the function at runtime. The database uses the index like normal.
Covering Indexes and Why They Help
A covering index goes a step further. It includes not just the column you’re filtering on, but also the ones you plan to read. That way the database doesn’t need to touch the base table at all. It finds what it needs inside the index alone.
Imagine a query like this:

That query filters on last_name and returns only department_id. A regular index on last_name helps with filtering, but it still needs to visit the row in the table to get department_id. That extra step is called a "table lookup" or "row fetch" and costs time.
Now compare it to this:

This index contains both columns. The query can use it for filtering and get the result directly without touching the base table:

This works best when you’re reading small sets of columns that line up with the index. It’s especially useful in reporting queries that need to filter and return compact results.
Covering indexes are read-only helpers. They don’t affect the table’s actual data but give the database a faster path when the stars align.
Index Order Matters
The order of columns in an index isn’t random. It controls how the index is sorted and what kinds of filters can use it. If your query doesn’t match that order, the index won’t help much.
Let’s say you create this:

That index sorts by last_name first, then by first_name. A filter like this will work well:

The index can jump to all rows with that last name, then walk through them.
This one works too:

It’s even more specific. But now look at this:

The database can’t use the index. That’s because it doesn’t know where to start without filtering on the leading column. It’s like trying to look someone up in a phone book sorted by last name when all you have is a first name.
You can always create another index for the other order if needed:

But keep in mind that every new index takes up space and adds some overhead to writes. It’s a tradeoff worth thinking about based on what queries matter most.
All of this shows that indexes aren’t just about what column you pick, they’re about how you write the query, what filters come first, and what the engine sees as usable. Writing fast queries means writing with the index in mind.
Filtering Smarter With Joins And Where Clauses
Joining tables is part of almost every real-world query, but joins can turn into a slowdown fast if they’re not written with care. It’s easy to bring in more rows than needed or to force the engine into matching everything before it filters anything. The way you write the join and where you put your filters directly affects how long the query takes and how much data it churns through.
When Joins Slow Things Down
A join takes two tables and links their rows based on a condition. But how many rows get pulled in depends on what you’re joining and when you’re filtering. Without limits in place, the engine might combine a huge number of rows before it filters anything out.
Here’s an example using orders and customers:
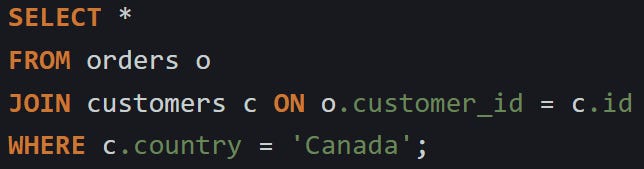
This runs fine if both tables are small. But with large datasets, the engine could end up reading every row in orders, matching them all to customers, and only then trimming the result to where the customer lives in Canada. That means a lot of unnecessary work upfront.
You can often shift the filter earlier by rewriting the query to limit the bigger table first:

This version gives the planner a smaller set of customer IDs to join against. It helps the database reduce the size of the join from the beginning instead of waiting until the very end.
In MySQL 8 and PostgreSQL, the planner is smart enough to pick the faster plan in some cases, but making it clearer with subqueries or Common Table Expressions can nudge it in the right direction when the automatic plan isn’t working well.
Filtering Early Helps the Optimizer
The planner picks the cheapest path by weighing indexes, table sizes, join types, and filter placement. It looks at indexes, table sizes, join types, and how filters are written. Giving it the best shot at skipping work early makes a real difference.
Here’s a join with a filter added after the fact:

Now compare that to this version:

Both versions give the same output, but the second one is easier for the planner to break down early. It can apply the filter as it builds the join instead of waiting until it’s done linking all the rows. That saves memory and processing time, especially with bigger tables.
Another thing to watch is how much gets filtered at each step. If you’re joining a million employees to fifty departments, trimming the department list from fifty to ten before the join saves a good chunk of work. And it’s not just about speed. Filtering early helps with stability. A query that joins too many rows all at once can run out of memory or hit temporary disk usage. Letting the engine work with fewer rows up front avoids that mess.
LEFT JOINs and WHERE Collisions
LEFT JOINs are great when you want to include rows from one table even if there’s no match in the other. But that behavior falls apart if you place filters in the wrong place. A WHERE clause can undo the whole point of the LEFT JOIN if it excludes rows that were meant to be kept.
Here’s a common mistake:

This filters out any post that didn’t get a comment. That means the LEFT JOIN turned into an INNER JOIN. All the rows where comments was null got tossed.
To fix that, put the filter inside the join condition:
Now it keeps the posts that had no comments and only shows flagged comments when they exist. This is a safer way to preserve the left-side rows while still trimming the right side. The same rule applies to other optional joins. Moving the filter into the ON clause tells the engine what to include in the join without risking the removal of rows that were supposed to stay.
Wildcards And LIKE Abuse
Searches using LIKE can cause trouble if they’re not shaped right. A query with a wildcard at the start forces the database to look at every row. It can’t use a sorted index when the search term floats in the middle.
Here’s a common example that slows things down:

This search checks every row and compares the string manually. The percent sign at the start means there’s no way to jump to where matches start. It’s a full scan no matter how many rows are in the table.
Now compare it with a search that starts with a known prefix:

That pattern can use an index, since the engine can skip straight to the part of the name column that starts with “wireless”. It doesn’t need to check the entire table.
Still, if you need to search within text, most databases offer full-text search tools that do this better. PostgreSQL has to_tsvector, MySQL supports FULLTEXT indexes, and SQLite includes FTS5.
Here’s what a full-text search looks like in PostgreSQL:

That uses a special index made for text search. It’s built to handle word lookups, phrases, and combinations without scanning every row.
For apps with search boxes, full-text search engines like PostgreSQL’s built-in support or even external tools like Elasticsearch or Meilisearch can take over this job entirely. But if you’re staying inside SQL, structure the query so the index works for you, not against you.
Conclusion
Fast queries come from working with the database’s mechanics, not around them. Indexes give it shortcuts, but only if the query lines up. Joins run faster when filters help early instead of late. Wildcards and misplaced conditions make the engine do more work than it needs to. Writing queries that run better starts with knowing how the planner thinks, what it looks at, and what slows it down. The shape of your query decides how much work happens behind the scenes. Trim the work, and the speed follows.

{kind=link}